I have two time series, shown in the plot below:
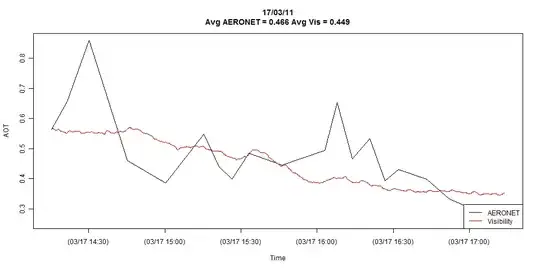
The plot is showing the full detail of both time series, but I can easily reduce it to just the coincident observations if needed.
My question is: What statistical methods can I use to assess the differences between the time series?
I know this is a fairly broad and vague question, but I can't seem to find much introductory material on this anywhere. As I can see it, there are two distinct things to assess:
1. Are the values the same?
2. Are the trends the same?
What sort of statistical tests would you suggest looking at to assess these questions? For question 1 I can obviously assess the means of the different datasets and look for significant differences in distributions, but is there a way of doing this that takes into account the time-series nature of the data?
For question 2 - is there something like the Mann-Kendall tests that looks for the similarity between two trends? I could do the Mann-Kendall test for both datasets and compare, but I don't know if that is a valid way to do things, or whether there is a better way?
I'm doing all of this in R, so if tests you suggest have a R package then please let me know.