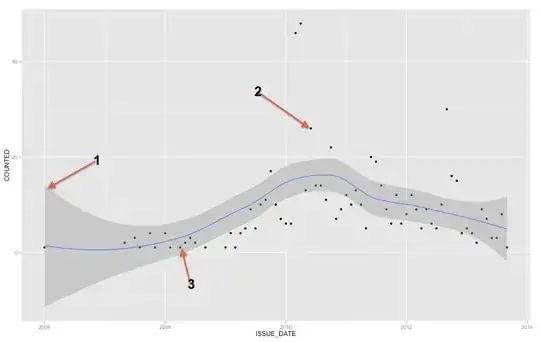
The gray band is a confidence band for the regression line. I'm not familiar enough with ggplot2 to know for sure whether it is a 1 SE confidence band or a 95% confidence band, but I believe it is the former (Edit: evidently it is a 95% CI). A confidence band provides a representation of the uncertainty about your regression line. In a sense, you could think that the true regression line is as high as the top of that band, as low as the bottom, or wiggling differently within the band. (Note that this explanation is intended to be intuitive, and is not technically correct, but the fully correct explanation is hard for most people to follow.)
You should use the confidence band to help you understand / think about the regression line. You should not use it to think about the raw data points. Remember that the regression line represents the mean of $Y$ at each point in $X$ (if you need to understand this more fully, it may help you to read my answer here: What is the intuition behind conditional Gaussian distributions?). On the other hand, you certainly do not expect every observed data point to be equal to the conditional mean. In other words, you should not use the confidence band to assess whether a data point is an outlier.
(Edit: this note is peripheral to the main question, but seeks to clarify a point for the OP.)
A polynomial regression is not a non-linear regression, even though what you get doesn't look like a straight line. The term 'linear' has a very specific meaning in a mathematical context, specifically, that the parameters you are estimating--the betas--are all coefficients. A polynomial regression just means that your covariates are $X$, $X^2$, $X^3$, etc., that is, they have a non-linear relation to each other, but your betas are still coefficients, thus it is still a linear model. If your betas were, say, exponents, then you would have a non-linear model.
In sum, whether or not a line looks straight has nothing to do with whether or not a model is linear. When you fit a polynomial model (say with $X$ and $X^2$), the model doesn't 'know' that, e.g., $X_2$ is actually just the square of $X_1$. It 'thinks' these are just two variables (although it may recognize that there is some multicollinearity). Thus, in truth it is fitting a (straight / flat) regression plane in a three dimensional space rather than a (curved) regression line in a two dimensional space. This is not useful for us to think about, and in fact, extremely difficult to see since $X^2$ is a perfect function of $X$. As a result, we don't bother thinking of it in this way and our plots are really two dimensional projections onto the $(X,\ Y)$ plane. Nonetheless, in the appropriate space, the line is actually 'straight' in some sense.
From a mathematical perspective, a model is linear if the parameters you are trying to estimate are coefficients. To clarify further, consider the comparison between the standard (OLS) linear regression model, and a simple logistic regression model presented in two different forms:
$$
Y = \beta_0 + \beta_1X + \varepsilon
$$
$$
\ln\left(\frac{\pi(Y)}{1 - \pi(Y)}\right) = \beta_0 + \beta_1X
$$
$$
\pi(Y) = \frac{\exp(\beta_0 + \beta_1X)}{1 + \exp(\beta_0 + \beta_1X)}
$$
The top model is OLS regression, and the bottom two are logistic regression, albeit presented in different ways. In all three cases, when you fit the model, you are estimating the $\beta$s. The top two models are linear, because all of the $\beta$s are coefficients, but the bottom model is non-linear (in this form) because the $\beta$s are exponents. (This may seem quite strange, but logistic regression is an instance of the generalized linear model, because it can be rewritten as a linear model. For more information about that, it may help to read my answer here: Difference between logit and probit models.)