There are an infinite number of ways of being non-Gaussian.
For example, you mentioned skewness and kurtosis - while those measures are certainly ways of identifying distributions that aren't Gaussian, and they can be combined into a single measure of deviation from Gaussian-ness* (and even form the basis of some common tests of normality), they're terrible at identifying distributions that have the same skewness and kurtosis as a normal but are distinctly non-normal.
* (see the tests by Bowman and Shenton and the better known - but less well-done, I think - work of Jarque and Bera)
Here's an example of the density of one such distribution:
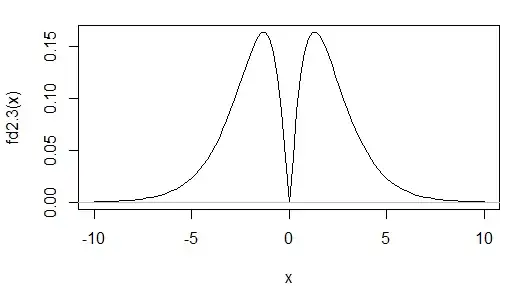
It's bimodal, but has skewness 0, and kurtosis 3.00 (to two d.p. -- i.e. an excess kurtosis of 0), the same as the normal.
A measure based on skewness and kurtosis is going to be terrible at identifying distributions such as these. Of course, if you're not worried about such possibilities, this may not matter -f you mainly want to pick up cases where the skewness and kurtosis deviate from those of the normal, a test based on those two measures is relatively powerful.
(Incidentally, the Shapiro-Wilk test is fairly good at spotting this one.)
Ultimately, choosing such a measure (whether you intend to formally test it or not) is a matter of finding things that are good at distinguishing the particular kinds of non-normality you care about. (In hypothesis-test-ese, the ones that have good power against the specific alternatives of interest.)
So work out what features you want to 'see' best, and choose a measure that is good at seeing those things.
The chi-square you mention probably refers to the chi-square goodness of fit test. It's generally a very weak test of goodness of fit for anything other than distributions over nominal categories. (Alternatively, it might be a reference to the asymptotic chi-square distribution of the Jarque-Bera type test. Be warned, the asymptotics there kick in very, very slowly indeed.)
Popular tests of normality would start with the Shapiro-Wilk and Shapiro-Francia. The Anderson-Darling** test can be adapted to work with parameter estimation and has good power. There's also smooth tests of goodness of fit (see the little book by Rayner and Best by that name, and their many papers, as well as the more recent book on Smooth tests in R); the smooth test for normality is quite powerful.
** With hypothesis tests that assume a completely specified distribution, such as the Kolmogorov-Smirnov and the Anderson-Darling, avoid using tests of normality based off estimated parameter values. The tests don't have the right properties, unless you account for that effect. In the case of the K-S, you end up with what's called a Lilliefors test. With the A-D it's still called an A-D test and if you check the book by D'Agostino & Stephens I mention below, there are approximations which adapt the usual test that seem to work quite well even with fairly small n.
If you don't want a formal hypothesis test, just about any of the usual test statistics can be adapted to be a measure that has some kind of interpretation or other as a measure of non-normality. For example, a Shapiro-Francia test statistic can be seen as a rescaled version of a squared correlation of observations with their normal scores (expected normal order statistics), and such a measure is an excellent accompaniment to a normal QQ plot.
I want to determine if these data are Gaussian.
I bet you a dollar they aren't Gaussian, and I bet you don't even need a test to tell that. What you really want to know is likely something else.
Note that usually the interesting question isn't 'are my data normal' (the answer is almost always 'obviously not', even before you collect any observations). The interesting question is 'how badly will the non-normality I have affect whatever I am trying to do?' ... and that's usually better judged by some measure of how non-normal it is, rather than a p-value.
Good places to start reading about goodness of fit (if you have access to a suitable library) would be the book Goodness of Fit Techniques by D'Agostino and Stephens and the aforementioned book on smooth tests by Rayner and Best; alternatively there are many papers and discussions you can find online, including many answers relating to goodness of fit here. Outside of some papers that are online, smooth tests can be hard to find information on, but one of Cosma Shalizi's courses has some excellent notes see here that serve as a (somewhat mathematical) introduction to the ideas.
[Goodness of fit is a surprisingly big area.]
For additional useful points, see also here or here or here or here