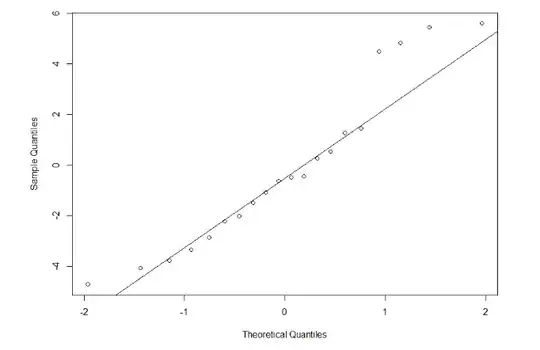
The ends of these graphs confuse me. I know most of the values fall on or near the line. But I am unsure of whether the data is indeed approximately normal. These are the two graphs.
Plot 1:
Plot 2:
The ends of these graphs confuse me. I know most of the values fall on or near the line. But I am unsure of whether the data is indeed approximately normal. These are the two graphs.
Plot 1:
Plot 2:
It's hard to say too much one way or the other from those plots. They certainly don't seem to deviate too wildly from the expected normal distribution shape. (Of course, they don't match perfectly either.) You may be OK with assuming normality, many tests are pretty robust to violations of the assumption of normality anyway.
On the other hand, you really are best off using methods that don't require these assumptions in the first place instead of checking and then choosing a test afterwards. (For more on that, it may help to read this excellent CV thread: How to choose between t-test or non-parametric test e.g. Wilcoxon in small samples.)
Use a Shapiro-Wilk test in R to test for normality. Null Hypothesis is Data is Normal.