I have a model that attempts to predict a nation's quality of life index by it's moral indifference to contraception and moral rejection of gambling. Initially the model contained several predictors, but I eliminated most using backwards elimination via AIC. Here is a summary of the model (generated using R):
> summary(fit1)
Call:
lm(formula = Quality.of.life.index ~ Morally.unacceptable.ga +
Not.a.moral.issue.co, data = qli_and_moral_ind)
Residuals:
Min 1Q Median 3Q Max
-89.670 -25.443 -4.732 36.129 64.441
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 143.1410 32.7499 4.371 0.00019 ***
Morally.unacceptable.ga -1.7690 0.3603 -4.910 4.71e-05 ***
Not.a.moral.issue.co 1.4471 0.7925 1.826 0.07981 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 40.39 on 25 degrees of freedom
Multiple R-squared: 0.6079, Adjusted R-squared: 0.5765
F-statistic: 19.38 on 2 and 25 DF, p-value: 8.266e-06
There are two plots of the model that I can't interpret:
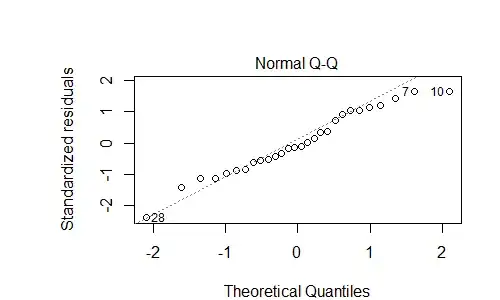
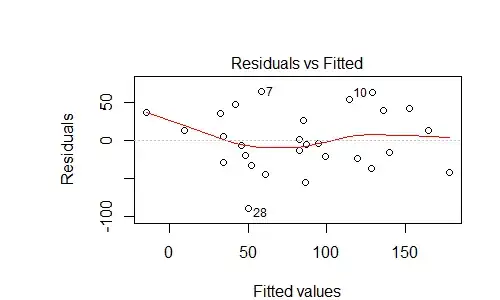
According to the web, the residuals plot above may indicate predictable error, ie that I'm missing some variable in my model. Is that assessment correct? If so, what should I consider adding to the model? It kind of looks like the $y = x^3 - x$ graph - maybe add a cubed term?