I have two classifiers
- A: naive Bayesian network
- B: tree (singly-connected) Bayesian network
In terms of accuracy and other measures, A performs comparatively worse than B. However, when I use the R packages ROCR and AUC to perform ROC analysis, it turns out that the AUC for A is higher than the AUC for B. Why is this happening?
The true positive (tp), false positive (fp), false negative (fn), true negative (tn), sensitivity (sen), specificity (spec), positive predictive value (ppv), negative predictive value (npv), and accuracy (acc) for A and B are as follows.
+------+---------+---------+
| | A | B |
+------+---------+---------+
| tp | 3601 | 769 |
| fp | 0 | 0 |
| fn | 6569 | 5918 |
| tn | 15655 | 19138 |
| sens | 0.35408 | 0.11500 |
| spec | 1.00000 | 1.00000 |
| ppv | 1.00000 | 1.00000 |
| npv | 0.70442 | 0.76381 |
| acc | 0.74563 | 0.77084 |
+------+---------+---------+
With the exception of sens and ties (spec and ppv) on the marginals (excluding tp, fn, fn, and tn), B seems to perform better than A.
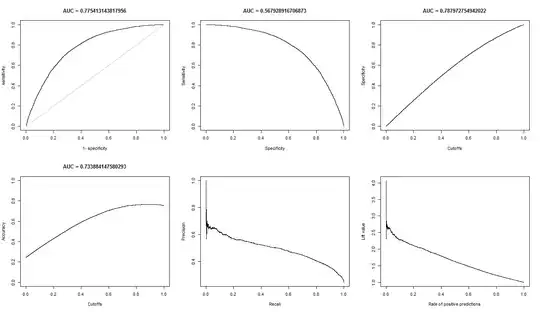
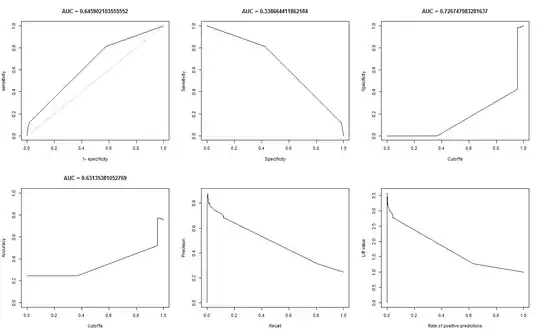
When I compute the AUC for sens (y-axis) vs 1-spec (x-axis)
aucroc <- auc(roc(data$prediction,data$labels));
here is the AUC comparison.
+----------------+---------+---------+
| | A | B |
+----------------+---------+---------+
| sens vs 1-spec | 0.77540 | 0.64590 |
| sens vs spec | 0.70770 | 0.61000 |
+----------------+---------+---------+
So here are my questions:
- Why is the AUC for A better than B, when B "seems" to outperform A with respect to accuracy?
- So, how do I really judge / compare the classification performances of A and B? I mean, do I use the AUC value? Do I use the acc value, and if so why?
- Furthermore, when I apply proper scoring rules to A and B, B outperforms A in terms of log loss, quadratic loss, and spherical loss (p < 0.001). How do these weigh in on judging classification performance with respect to AUC?
- The ROC graph for A looks very smooth (it is a curved arc), but the ROC graph for B looks like a set of connected lines. Why is this?
As requested, here are the plots for model A.
Here are the plots for model B.
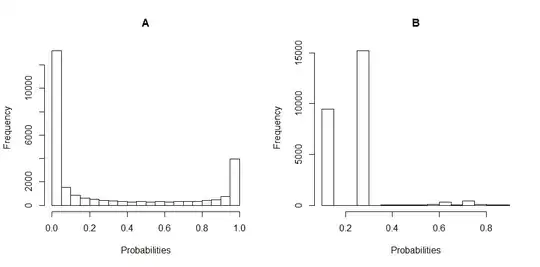
Here are the histogram plots of the distribution of the probabilities for A and B. (breaks are set to 20).
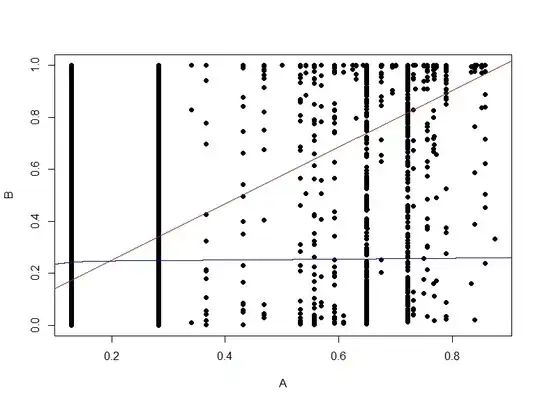
Here is the scatter plot of the probabilities of B vs A.