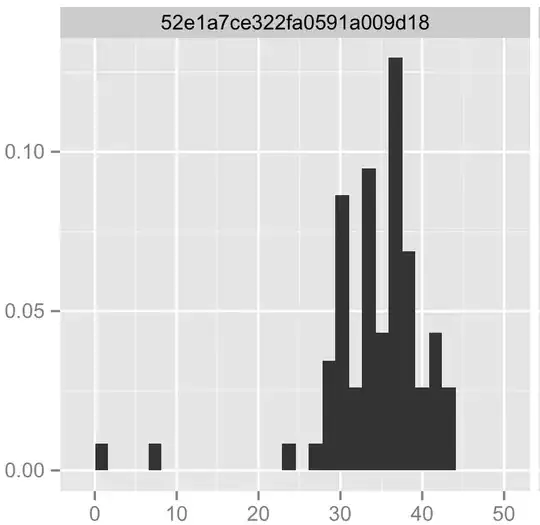
I am designing a points-scored test. There is a limit on the maximum amount of points possible, as well as on the fewest amount of points possible. I have had a test group take the test and graphed their results, which form a lopsided bell curve or sorts. I am trying to figure out what kind of distribution would be best to describe this distribution, for the purpose of using it to calculate percentile scores for any future test takers. I would use normal, but intuitively, I feel that the highest percentiles would never be reached, since they would be beyond the upper bound of the data set. Would a truncated normal distribution or beta distribution be best? Any help, intuitive or direct, would be appreciated. I am mostly working in the R environment.