I have a semi-small matrix of binary features of dimension 250k x 100. Each row is a user and the columns are binary "tags" of some user behavior e.g. "likes_cats".
user 1 2 3 4 5 ...
-------------------------
A 1 0 1 0 1
B 0 1 0 1 0
C 1 0 0 1 0
I would like to fit the users into 5-10 clusters and analyze the loadings to see if I can interpret groups of user behavior. There appears to be quite a few approaches to fitting clusters on binary data - what do we think might be the best strategy for this data?
PCA
Making a Jaccard Similarity matrix, fitting a hierarchical cluster and then using the top "nodes".
K-medians
K-medoids
Agnes
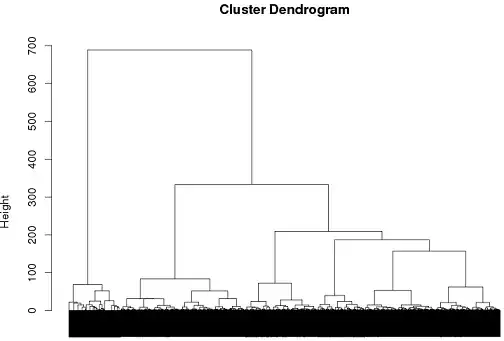
So far I've had some success with using hierarchical clustering but I'm really not sure it's the best way to go..
tags = read.csv("~/tags.csv")
d = dist(tags, method = "binary")
hc = hclust(d, method="ward")
plot(hc)
cluster.means = aggregate(tags,by=list(cutree(hc, k = 6)), mean)