In short: Maximising the margin can more generally be seen as regularising the solution by minimising $w$ (which is essentially minimising model complexity) this is done both in the classification and regression. But in the case of classification this minimisation is done under the condition that all examples are classified correctly and in the case of regression under the condition that the value $y$ of all examples deviates less than the required accuracy $\epsilon$ from $f(x)$ for regression.
In order to understand how you go from classification to regression it helps to see how both cases one applies the same SVM theory to formulate the problem as a convex optimisation problem. I'll try putting both side by side.
(I'll ignore slack variables that allow for misclassifications and deviations above accuracy $\epsilon$)
Classification
In this case the goal is to find a function $f(x)= wx +b$ where $f(x) \geq 1$ for positive examples and $f(x) \leq -1$ for negative examples. Under these conditions we want to maximise the margin (distance between the 2 red bars) which is nothing more than minimising the derivative of $f'=w$.
The intuition behind maximising the margin is that this will give us a unique solution to the problem of finding $f(x)$ (i.e. we discard for example the blue line) and also that this solution is the most general under these conditions, i.e. it acts as a regularisation. This can be seen as, around the decision boundary (where red and black lines cross) the classification uncertainty is the biggest and choosing the lowest value for $f(x)$ in this region will yield the most general solution.
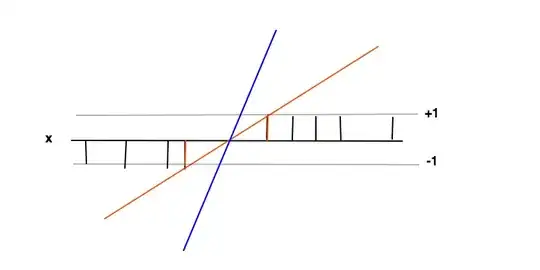
The data points at the 2 red bars are the support vectors in this case, they correspond to the non-zero Lagrange multipliers of the equality part of the inequality conditions $f(x) \geq 1$ and $f(x) \leq -1$
Regression
In this case the goal is to find a function $f(x)= wx +b$ (red line) under the condition that $f(x)$ is within a required accuracy $\epsilon$ from the value value $y(x)$ (black bars) of every data point, i.e. $|y(x) -f(x)|\leq \epsilon$ where $epsilon$ is the distance between the red and the grey line. Under this condition we again want to minimise $f'(x)=w$, again for the reason of regularisation and to obtain a unique solution as the result of the convex optimisation problem. One can see how minimising $w$ results in a more general case as the extreme value of $w=0$ would mean no functional relation at all which is the most general result one can obtain from the data.
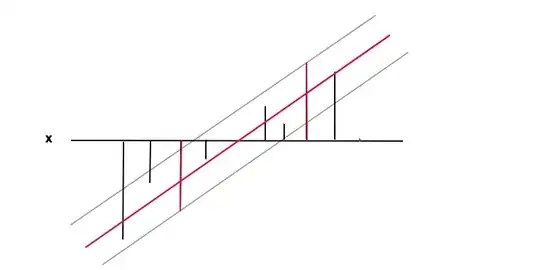
The data points at the 2 red bars are the support vectors in this case, they correspond to the non-zero Lagrange multipliers of the equality part of the inequality condition $|y -f(x)|\leq \epsilon$.
Conclusion
Both cases result in the following problem:
$$ \text{min} \frac{1}{2}w^2 $$
Under the condition that:
- All examples are classified correctly (Classification)
- The value $y$ of all examples deviates less than $\epsilon$ from $f(x)$. (Regression)