I have been trying to establish whether I could model my data, a set of 90 observations, using the normal distribution. I have tried the Shapiro-Wilk and the Anderson-Darling tests but each came back with a different result.
Anderson-Darling normality test
data: x A = 0.6994, p-value = 0.06555
Shapiro-Wilk normality test
data: x W = 0.9645, p-value = 0.0154
If we are to use the strong 1% significance level, the null of normality cannot be rejected in either case. Using the 5% size, however, we see that the SW test rejects the null while the AD one narrowly accepts it.
The results are conflicting and I do not know on which to place my trust. If I knew the power of each test, I could make up my mind so is there perhaps a way to obtain the power functions in R? The Normal distribution is easy to work with and it would make sense in my case seeing that my observations are test scores but I do not want to make farfetched assumptions.
I also have to say that personally, I am not convinced that the underlying distribution is normal. Please take a look at the histogram below, upon which I have fitted a normal distribution with the same mean and standard deviation.
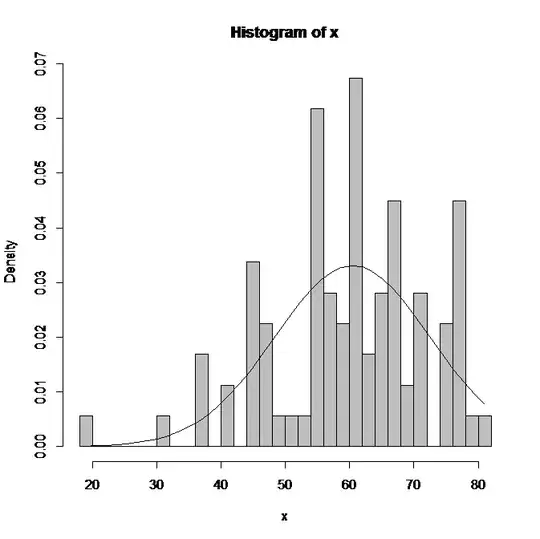
It does not seem to be a good match. Below is the normal qq plot:
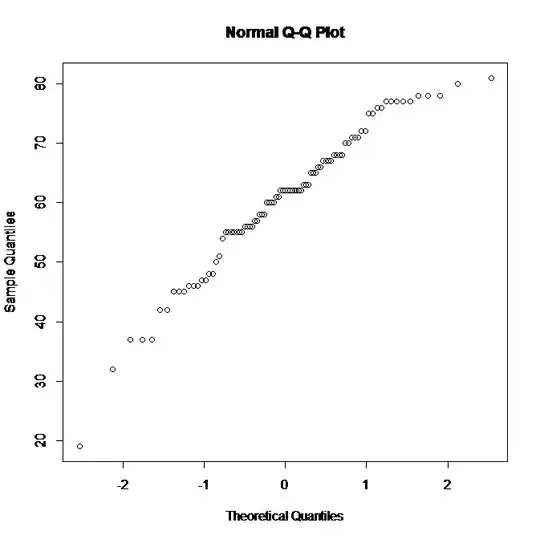
There is a hint of linearity but there are also a lot of outliers. As far as I know, the Shapiro-Wilk test is based on order statistics and it does not support the normality hypothesis.
If we were to reject the normality of my data, then what would be an acceptable distribution here? Note that we are looking for a negatively skewed one.
All suggestions are welcome. Thank you.
EDIT: This is my vector of observations in ascending order, i.e. the 89 order statistics, in case anyone wants to test it further:
sort(x)
19 32 37 37 37 42 42 45 45 45 46 46 46 47 47 48 48 50 51 54 55 55 55 55 55 55 55 56 56 56 56 57 57 58 58 58 60 60 60 60 61 61 62 62 62 62 62 62 62 62 62 62 63 63 63 65 65 65 66 66 67 67 67 67 68 68 68 68 70 70 71 71 71 72 72 75 75 76 76 77 77 77 77 77 78 78 78 80 81