This question calls for a modification of the solution to a sequence counting problem: as noted in comments, it requests a cross-tabulation of co-occurrences of values.
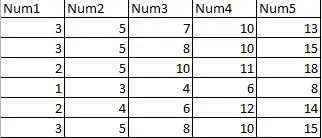
I will illustrate a naive but effective modification with R code. First, let's introduce a small sample dataset to work with. It's in the usual matrix format, one case per row.
x <- matrix(c(3,5,7,10,13,
3,5,8,10,15,
2,5,10,11,18,
1,3,4,6,8,
2,4,6,12,14,
3,5,8,10,15),
ncol=5, byrow=TRUE)
This solution generates all possible combinations of $m$ items (per row) at a time and tabulates them:
m <- 3
x <- t(apply(x, 1, sort))
x0 <- apply(x, 1, combn, m=m)
y <- array(x0, c(m, length(x0)/(m*dim(x)[1]), dim(x)[1]))
ngrams <- apply(y, c(2,3), function(s) paste("(", paste(s, collapse=","), ")", sep=""))
z <- sort(table(as.factor(ngrams)), decreasing=TRUE)
The tabulation is in z, sorted by descending frequency. It is useful by itself or easily post-processed. Here are the first few entries of the example:
> head(z, 10)
(3,5,10) (3,10,15) (3,5,15) (3,5,8) ... (8,10,15)
3 2 2 2 ... 2
How efficient is this? For $p$ columns there are $\binom{p}{m}$ combinations to work out, which grows as $O(p^m)$ for fixed $m$: that's pretty bad, so we are limited to relatively small numbers of columns. To get a sense of the timing, repeat the preceding with a small random matrix and time it. Let's stick with values between $1$ and $20,$ say:
n.col <- 8 # Number of columns
n.cases <- 10^3 # Number of rows
x <- matrix(sample.int(20, size=n.col*n.cases, replace=TRUE), ncol=n.col)
The operation took two seconds to tabulate all $m=3$-combinations for $1000$ rows and $8$ columns. (It can go an order of magnitude faster by encoding the combinations numerically rather than as strings; this is limited to cases where $\binom{p}{m}$ is small enough to be represented exactly as an integer or float, limiting it to approximately $10^{16}$.) It scales linearly with the number of rows. (Increasing the number of possible values from $20$ to $20,000$ only slightly lengthened the time.) If that suggests overly long times to process a particular dataset, then a more sophisticated approach will be needed, perhaps utilizing results for very small $m$ to limit the higher-order combinations that are computed and counted.