In my opinion, the model that you've described doesn't really lend itself to plotting, as plots function best when they display complex information that is hard to understand otherwise (e.g., complex interactions). However, if you'd like to display a plot of the relationships in your model, you've got two main options:
- Display a series of plots of the bivariate relationships between each of your predictors of interest and your outcome, with a scatterplot of the raw datapoints. Plot error envelopes around your lines.
- Display the plot from option 1, but instead of showing the raw datapoints, show the datapoints with your other predictors marginalized out (i.e., after subtracting out the contributions of the other predictors)
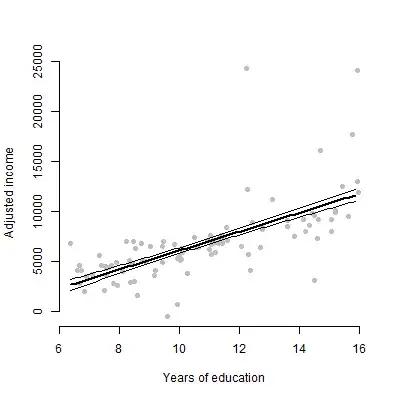
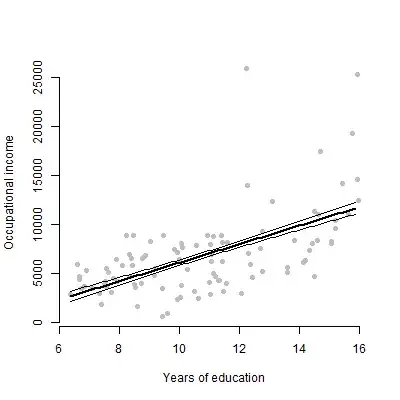
The benefit of option 1 is that it allows the viewer to assess the scatter in the raw data. The benefit of option 2 is that it shows the observation-level error that actually resulted in the standard error of the focal coefficient that you're displaying.
I have included R code and a graph of each option below, using data from Prestige dataset in the car package in R.
## Raw data ##
mod <- lm(income ~ education + women, data = Prestige)
summary(mod)
# Create a scatterplot of education against income
plot(Prestige$education, Prestige$income, xlab = "Years of education",
ylab = "Occupational income", bty = "n", pch = 16, col = "grey")
# Create a dataframe representing the values on the predictors for which we
# want predictions
pX <- expand.grid(education = seq(min(Prestige$education), max(Prestige$education), by = .1),
women = mean(Prestige$women))
# Get predicted values
pY <- predict(mod, pX, se.fit = T)
lines(pX$education, pY$fit, lwd = 2) # Prediction line
lines(pX$education, pY$fit - pY$se.fit) # -1 SE
lines(pX$education, pY$fit + pY$se.fit) # +1 SE
## Adjusted (marginalized) data ##
mod <- lm(income ~ education + women, data = Prestige)
summary(mod)
# Calculate the values of income, marginalizing out the effect of percentage women
margin_income <- coef(mod)["(Intercept)"] + coef(mod)["education"] * Prestige$education +
coef(mod)["women"] * mean(Prestige$women) + residuals(mod)
# Create a scatterplot of education against income
plot(Prestige$education, margin_income, xlab = "Years of education",
ylab = "Adjusted income", bty = "n", pch = 16, col = "grey")
# Create a dataframe representing the values on the predictors for which we
# want predictions
pX <- expand.grid(education = seq(min(Prestige$education), max(Prestige$education), by = .1),
women = mean(Prestige$women))
# Get predicted values
pY <- predict(mod, pX, se.fit = T)
lines(pX$education, pY$fit, lwd = 2) # Prediction line
lines(pX$education, pY$fit - pY$se.fit) # -1 SE
lines(pX$education, pY$fit + pY$se.fit) # +1 SE