Can you give the reason for using a one tailed test in the analysis of variance test?
Why do we use a one-tail test - the F-test - in ANOVA?
Can you give the reason for using a one tailed test in the analysis of variance test?
Why do we use a one-tail test - the F-test - in ANOVA?
F tests are most commonly used for two purposes:
in ANOVA, for testing equality of means (and various similar analyses); and
in testing equality of variances
Let's consider each in turn:
1) F tests in ANOVA (and similarly, the usual kinds of chi-square tests for count data) are constructed so that the more the data are consistent with the alternative hypothesis, the larger the test statistic tends to be, while arrangements of sample data that looks most consistent with the null corresponds to the smallest values of the test statistic.
Consider three samples (of size 10, with equal sample variance), and arrange them to have equal sample means, and then move their means around in different patterns. As the variation in the sample means increases from zero, the F statistic becomes larger:
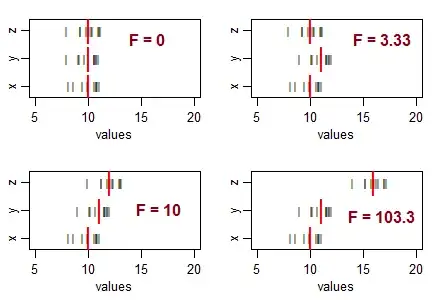
The black lines ($^{\:_|}$) are the data values. The heavy red lines ($\color{red}{\mathbf{|}}$) are the group means.
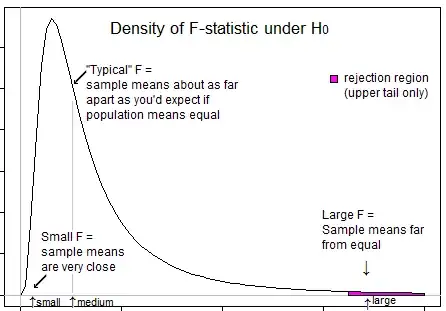
If the null hypothesis (equality of population means) were true, you'd expect some variation in sample means, and would typically expect to see F ratios roughly around 1. Smaller F statistics result from samples that are closer together than you'd typically expect ... so you aren't going to conclude the population means differ.
That is, for ANOVA, you'll reject the hypothesis of equality of means when you get unusually large F-values and you won't reject the hypothesis of equality of means when you get unusually small values (it may indicate something, but not that the population means differ).
Here's an illustration that might help you see that we only want to reject when F is in its upper tail:
2) F tests for equality of variance* (based on variance ratios). Here, the ratio of two sample variance estimates will be large if the numerator sample variance is much larger than the variance in the denominator, and the ratio will be small if the denominator sample variance is much larger than variance in the numerator.
That is, for testing whether the ratio of population variances differs from 1, you'll want to reject the null for both large and small values of F.
* (Leaving aside the issue of the high sensitivity to the distributional assumption of this test (there are better alternatives) and also the issue that if you're interested in suitability of ANOVA equal-variance assumptions, your best strategy probably isn't a formal test.)
It must be understood that the objective of ANOVA is to check whether there is inequality of means...which implies that we are concerned with large variations between samples (& thus means as variations are computed from the means) as compared with variations within samples (again computed from individual sample mean). When the variations between samples is small (resulting in F value being on the left side) it does not matter as this difference is insignificant. The variations between samples matters if it is significantly higher than the within variations & in such case the F value would be greater than 1, & therefore in the right tail.
The only question remains is why put the entire level of significance in the right tail & the answer is again similar. THe rejection happens only when the F ratio is on the right side & never when the F ratio is on the left side. The level of significance is the measure of error due to statistical limitations. As the rejection happens only on the right the entire level of significance (error risk of misconclusion) is kept in the right. `
The expected value for the Mean Square (MS) within treatments is the population variance, whereas the expected value for the MS between treatments is the population variance PLUS the treatment variance. Thus, the ratio of F = MSbetween / MSwithin is always greater than 1, and never less than 1.
Since the precision of a 1-tailed test is better than a 2-tailed test, we prefer to use the 1-tailed test.