Study design
In our study, we have a 2x2x2 design with factors Prime (determiner, pronoun), Category (noun, verb) and Masking (masked presentation, unmasked presentation).
Our stimulus set included two prime words (determiner 'a' and pronoun 'he') and 80 target words (40 nouns and 40 verbs).
Linear mixed models in R
We have applied linear mixed models to the log-transformed reaction times.
We used the package lme4 in R, function lmer(), REML was set to FALSE.
To compare the models, we performed the likelihood ratio tests using the anova() function.
As random effects, we included random intercepts for participant (1|Participant), target word (1|Target word) and block number (1|Block).
Question
For example, in the model
lmer(lgRT ~ Category*Prime + (1|Participant) + (1|Target word) +
(1|Block), data=my_data_clean_masked, REML=FALSE)
Is it legitimate to include (1|Target word) as a random effect given that:
(1) the fixed effect "Category" has two levels: noun and verb;
(2) however, not all target words fall in the category NOUN (or VERB) because half of the target words was nouns and the other half was verbs?
In other words, nouns among the target words never belong to the word category VERB and verbs among the target words never belong to the word category NOUN.
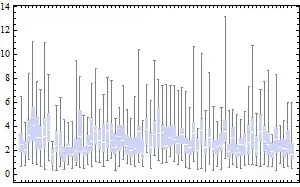
The residuals plot looks fine when three random effects are included ((1|Participant) + (1|Target word) + (1|Block)):
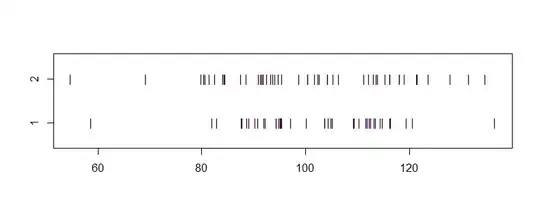
However, excluding the random effect (1|Target word) creates patterns on the residuals plot (the homoscedasticity seems to be violated, right?):