A "modern" (post-1900) view of tensors is a geometric one. Perhaps the clearest notation would therefore be a figure, because the "normal equations" are nothing more than a familiar, ages-old theorem of plane geometry!
As a point of departure, let's begin with an expression from your previous question. The setting is Ordinary least squares (OLS). The data are the "design matrix" $(x_{i,j})$, $1 \le i \le n$, $1 \le j \le p$ of "independent variables" and a vector of values of the "dependent variable" $y = (y_i)$, $1 \le i \le n$; each dependent value $y_i$ is associated with the $p$-tuple of independent values $(x_{i,1}, x_{i,2}, \ldots, x_{i,p}).$
OLS aims to find a vector $\beta = (\beta_1, \beta_2, \ldots, \beta_p)$ minimizing the sum of squares of residuals
$$\sum_{i=1}^n\left(y_i - \sum_{j=1}^p \left(x_{i,j}\beta_j\right)\right)^2.$$
Geometrically, the inner sum of products represents the application of the linear transformation determined by the matrix $x = (x_{i,j})$ to the $p$-vector $\beta$. As such we conceive of $x$ as representing a map $x: \mathbb{R}^p\to \mathbb{R}^n$. The outer sum is the usual Pythagorean formula for the Euclidean distance. Geometrically, then,
OLS seeks a vector $\hat\beta \in \mathbb{R}^p$ for which $x\hat\beta\in \mathbb{R}^n$ is as close to $y$ as possible.
The test of this is to take any other vector $\beta'\in \mathbb{R}^p$ and to compare distances within the triangle formed by the three points $y$, $x\hat\beta$, and $x\beta'$:
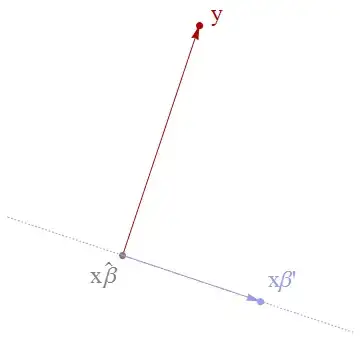
According to Euclid, three (distinct) points determine a plane, so the figure is utterly faithful: all our work is done within this plane.
We also know from Euclid that the ray $y - x\hat\beta$ must be perpendicular to the ray $x\beta' - x\hat\beta$. (This is the heart of the matter; in making this observation, we are really done and all that remains is to write down an equation expressing this perpendicularity.) Modern geometry has several notations for perpendicularity, which involves the (usual) "dot product" or positive-definite linear form (a "tensor of type $(2,0)$" if you wish). I will write it as $\langle\ ,\ \rangle$, whence we have deduced
$$\langle x\beta', y-x\hat\beta\rangle = 0$$
for all $\beta\in\mathbb{R}^p$. Because the usual dot product of two vectors in $\mathbb{R}^n$ is
$$\langle u, v\rangle = u^\intercal v,$$
the preceding may be written
$$\beta'^\intercal x^\intercal (y - x\hat\beta) = 0.$$
Geometrically, this says that the linear transformation from $\mathbb{R}^{p*}\to\mathbb{R}^n$ defined by applying $x^\intercal (y - x\hat\beta)$ to $\beta'^\intercal$ is the zero transformation, whence its matrix representation must be identically zero:
$$x^\intercal (y - x\hat\beta) = 0.$$
We are done; the conventional notation
$$\hat\beta = \left(x^\intercal x\right)^{-}\left(x^\intercal y\right)$$
(where "$\left(\right)^{-}$" represents a generalized inverse) is merely an algebraically suggestive way of stating the same thing. Most computations do not actually compute the (generalized) inverse but instead solve the preceding equation directly.
If, as an educational exercise, you really, really want to write things out in coordinates, then I would recommend adopting coordinates appropriate to this configuration. Choosing an orthonormal basis for $\mathbb{R}^n$ adapted to the plane determined by $y$ and $x\beta'$ for some arbitrary $\beta'$ allows you to forget the remaining $n-2$ coordinates, because they will be constantly $0$. Whence $y$ can be written $(\eta_1, \eta_2)$, $x$ can be written $(\xi_1, \xi_2)$, and $\beta'$ can be considered a number. We seek to minimize
$$\sum_{i=1}^n\left(y_i - \sum_{j=1}^p \left(x_{i,j}\beta_j\right)\right)^2=\left(\eta_1 - \xi_1 \beta\right)^2 + \left(\eta_2 - \xi_2 \beta\right)^2.$$
OLS claims that this is achieved for
$$\hat\beta = \left(x^\intercal x\right)^{-}\left(x^\intercal y\right)=\left(\xi_1^2 + \xi_2^2\right)^{-1}\left(\xi_1 \eta_1 + \xi_2 \eta_2\right)$$
provided $\xi_1^2 + \xi_2^2 \ne 0$. An elementary way to show this is to expand the former expression into powers of $\beta$ and apply the Quadratic Formula.