I am ripping my head off right now. I have beensitting all day, and tried to solve this assigment i have in statistics.
I have 5 observations: 229, 211, 93, 35, 8
I have 5 Expected observations: 226.74, 211.39, 98.54, 30.62, 8.71
I have to make a goodness of fit test of these numbers therefore i started to find G:
2 * (229 * ln(229 / (226.74)) + 211 * ln(211 / (211.39)) + 93 *
ln(93 / (98.54)) + 35 * ln(35 / (30.62)) +
8 * ln(8 / (8.71))) = 0.9987
or
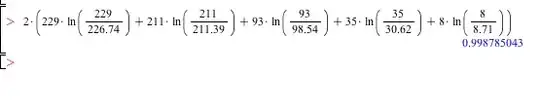
So now i have my:
lower value = 0.9987 and
df = 4
So now i have to find my pvalue through cdc(lower value, df) ? I cant seem to get anything right here, and i dont know if i have done it the correct way until now? Do anyone have an idea on how i could solve this? And incase how i type it in R or Maple?