The square root is approximately variance-stabilizing for the Poisson. There are a number of variations on the square root that improve the properties, such as adding $\frac{3}{8}$ before taking the square root, or the Freeman-Tukey ($\sqrt{X}+\sqrt{X+1}$ - though it's often adjusted for the mean as well).
In the plots below, we have a Poisson $Y$ vs a predictor $x$ (with mean of $Y$ a multiple of $x$), and then $\sqrt{Y}$ vs $\sqrt{x}$ and then $\sqrt{Y+\frac{3}{8}}$ vs $\sqrt{x}$.
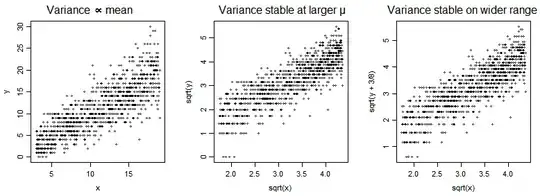
The square root transformation somewhat improves symmetry - though not as well as the $\frac{2}{3}$ power does [1]:
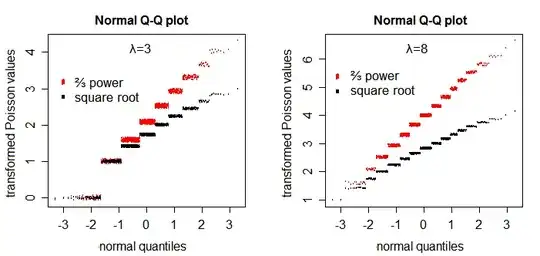
If you particularly want near-normality (as long as the parameter of the Poisson is not really small) and don't care about/can adjust for heteroscedasticity, try $\frac{2}{3}$ power.
The canonical link is not generally a particularly good transformation for Poisson data; log zero being a particular issue (another is heteroskedasticity; you can also get left-skewness even when you don't have 0's). If the smallest values are not too close to 0 it can be useful for linearizing the mean. It's a good 'transformation' for the conditional population mean of a Poisson in a number of contexts, but not always of Poisson data. However if you do want to transform, one common strategy is to add a constant $y^*=\log(y+c)$ which avoids the $0$ issue. In that case we should consider what constant to add. Without getting too far from the question at hand, values of $c$ between $0.4$ and $0.5$ work very well (e.g. in relation to bias in the slope estimate) across a range of $\mu$ values. I usually just use $\frac12$ since it's simple, with values around $0.43$ often doing just slightly better.
As for why people choose one transformation over another (or none) -- that's really a matter of what they're doing it to achieve.
[1]: Plots patterned after Henrik Bengtsson's plots in his handout "Generalized Linear Models and Transformed
Residuals" see here
(see first slide on p4). I added a little y-jitter and omitted the lines.