The Kolmogorov-Smirnov test is designed for situations where a continuous distribution is fully specified under the null hypothesis.
Let's look at what happens with the null distribution of the test statistic when the null hypothesis is true.
When you estimate parameters, the estimation identifies parameters that make the estimated distribution closer to the data than the population distribution is.
Let's take the slightly simpler example; the normal.
Here I generate a sample of 100 values from a $N(50,5)$ (the black points in the ECDF) and compare to the population distribution function (in blue) and the fitted distribution function (normal with the mean and variance set to the sample mean and variance, shown in red):
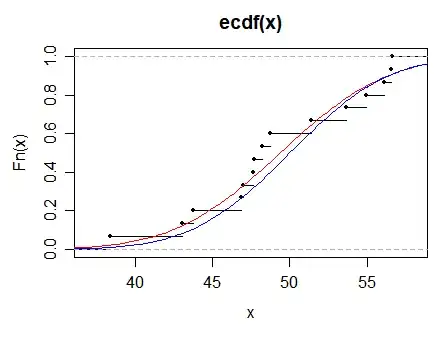
KS statistic for population parameters: D = 0.19987
KS statistic for fitted distribution: D = 0.14715
This it typical. However, it is possible for the statistic to be larger on the fitted because we don't actually fit the distribution by minimizing the KS statistic; if we did estimate parameters that way the fitted normal distribution would be guaranteed to have a smaller test statistic.
This "fitted is closer to the data than the population" is the same thing that results in dividing by $n-1$ in sample variance (Bessel-correction); here it makes the test statistic typically smaller than it should be.
So if you stuck with the usual tables the type I error rate would be smaller than you chose it to be (with corresponding lowering of power); your test doesn't behave the way you want it to.
You may like to read about Lilliefors test (on which there are many posts here). Lilliefors computed (via simulation) the distribution of a Kolmogorov-Smirnov statistic on fitted distributions under normal (unknown $\mu$, unknown $\sigma$, and both parameters unknown) and exponential cases (1967,1969)
Once you fit a distribution, the test is no longer distribution-free.
In the case where you're fitting the degrees of freedom parameter, I don't think Lilliefors approach will work for the t-distibution*; the advice to use bootstrapping may be reasonable in large samples.
* because the distribution of the test statistic will be different for different df (however, it might be that it doesn't vary much with df in which case you could still have a reasonable approximate test)
