I am using R to examine the relationship between two variables in a small data set ($n=16$).
My problem is that I'm not really sure how to handle the analysis (read: I'm in deeper waters than I've traveled before).
Do I use Spearman's Rho to calculate the rank coefficient? Or do I assume normality and use standard parametric tests (Pearson's)? Or do I transform the data, and then do the parametric tests? Or should I do something else?
My initial feeling is that I should use non-parametric tests on this data set for various reasons:
- I feel strongly that there is an upper and lower bound to the possible values observed for either the dependent or independent variable.
- I do not feel that the relationship between the variables is linear. I've provided the QQ Plot of the dependent variable, and the scatterplot of the dep & indep vars below, and neither seems to adhere to the normality assumptions:
The thing is, I'm getting hung up on several things:
- the Pearson's coefficient seems really high 0.94366 which makes me wonder if I'm sacrificing something by using Spearman's instead (for the sake of full disclosure, the Spearman's coefficient of 0.86765 is also significant at $\alpha = .001$). Now Answered
- If Spearman's is the answer, what is the next step in building a predictive model? Now Answered
- Since the sample is relatively small, should I use some kind of resampling to calculate the correlation instead of just using the 16 values?
- What other major things might I be overlooking?
Plots
QQ Plot of Indep Var:
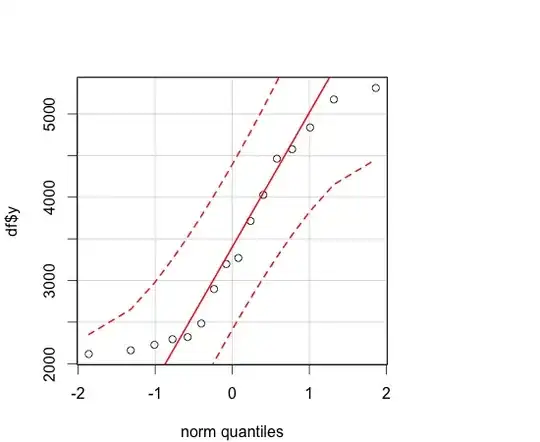 http://dl.dropbox.com/u/27272488/qqPlotY.png
http://dl.dropbox.com/u/27272488/qqPlotY.png
{kind=link}
Scatterplot of Dep & Indep Vars:
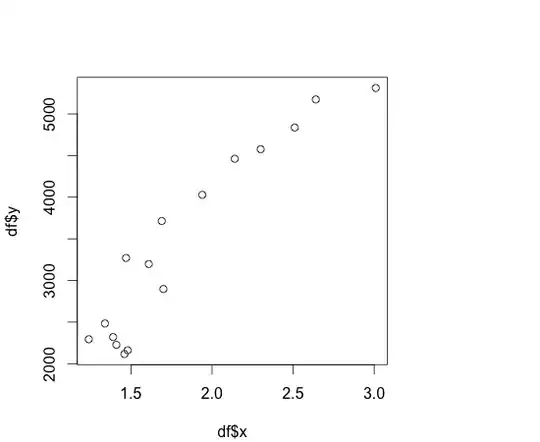 http://dl.dropbox.com/u/27272488/XvsY.png
http://dl.dropbox.com/u/27272488/XvsY.png
{kind=link}
Data
> df$year
[1] 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
> df$x
[1] 1.39 1.41 1.48 1.46 1.24 1.34 1.70 1.61 1.47 1.69 1.94 2.30 2.51 2.64 3.01 2.14
> df$y
[1] 2320 2227 2161 2116 2294 2483 2897 3197 3270 3714 4028 4576 4837 5174 5312 4462