It is described in Michael Friendly's American Statistician paper on corrgrams, Preprint PDF here. See section on correlation ordering. Also if you look at the source of the corrgram library you will see some other potential ways to order the data as well.
To describe what the code is doing in a nut-shell, the variables in the correlation matrix are ordered according to the correlations with the first and the second principle components extracted from that same correlation matrix. If you look at the Eigenvector plot in the Friendly paper (Figure 3), the code atan(e2/e1) is the angle between the ray associated with a particular variable and the horizontal axis. The variables are sorted by this angle, in a counter-clockwise order. If the whole picture were squeezed horizontally by the square root of the first eigenvalue, and vertically by the square root of the second eigenvalue (this would not change the order!), then the $x$ and $y$ coordinates of each ray's endpoint would be exactly the correlations of this variable with PC1 and with PC2.
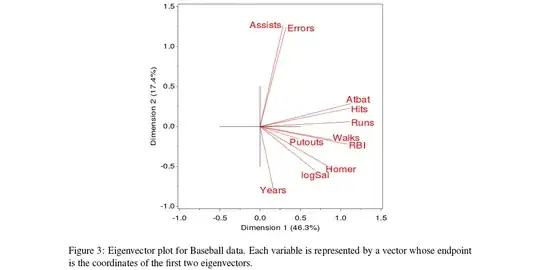
Again the reason for the ordering is given in the Friendly paper, but we almost always want more similar things next to more similar things (in either graphics or tables). Frequently the ordering is more informative than the numbers or the graph! Here in this example "more similar" is defined in terms of correlations to the first and the second principle components.
Also note I assume the first if statement in the code prevents this ordering from occurring if the correlation matrix is not full rank.