First of all, I appreciate lot of creator of this web and any attention on this question.
I asked related question here: 52 variables after backward variable selection on logistic regression on 160 variable at beginning, whether it is illusion or good modeling . The Statistic Guru @PeterFlom pointed out my naive choice to dichotomize the positive value of volatility whose self-correlated characteristics also violated the assumption that residuals should be independent. I totally agree with his opinion and thank him again for the precious time and patience from him. I really learned lot.
Now I changed my target and modelling way, little bit long description again below:
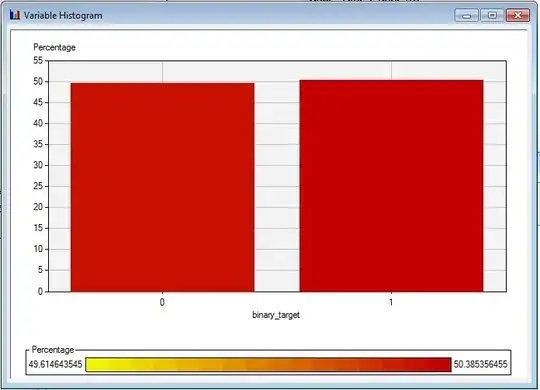
- Target Variable: Binary Target of day T + 1: if the close price is higher than the open price of EURUSD, I mark it as 1, and if the close price is lower than the open price of EURUSD< I mark it as 0. Little assessment: this time I believe here is not violation of assumption about independent residual like the one we had in volatility. We know volatility has kind of self-correlated characteristics, But in my humble opinion, here is no similar characteristics for the up and down of the Price.The distribution of the target looks like this pic:
Predictor Variable: again, frequency of 160 trading related key words from famous trading online forum. For example, the word “trader” in 2008-01-01 we found it occurred for 50 times and we found in 2008-01-01 we have totally 500 posts on that forum. Therefore, we kind of normalize the appearance of "trader" by dividing 50 of "trader" by 500 of "number of posts". We got 0.1 here for 2008-01-01. We have 160 words dictionary and the training data is from 2008-01-01 to 2011-12-31. Each row has 160 column with number indicating the frequency of specific words. That is all. Nothing variable of price, volatility here. Kind of pure sentiment data based on frequency counting. @gung I normalize the frequency by the reply number of day T, do you think I should still use log on the normalized frequency which is usually less than 1?
The goal and story line: whether we could use the combination of frequency of words could predict whether tomorrow Day T + 1 is up or down. The reason why I do not use linear regression to predict exact log return or percentage return is because the most words normalized frequency distributed in this way and not easy to transform them in to regular distribution shape, like normal distribution, that is why I give up on predicting the EXACT change of price, Please have a look on the distribution of "limit" and "Correction":
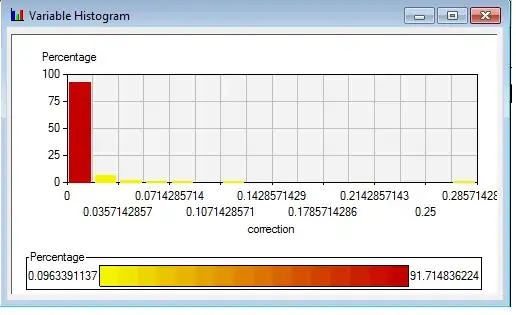
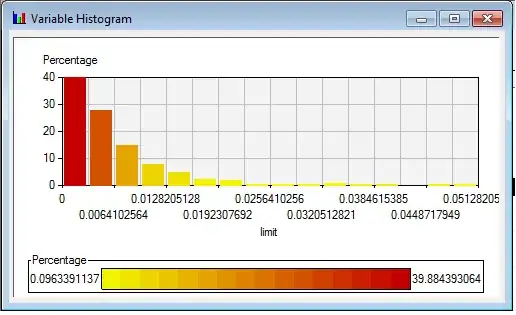
Again: Software I use: SAS Enterprese Miner 3 in SAS 9.1.3. Here is definition and details of modeling: A. I select logistic regression B. No data partition because I only have 1000days as my training data so I select to use complete data which means no sampling process and only training data. C. I select the backward as we want to see what are those significant predictor out of 160, here is some shortage if using forward. D. There is no validation data set so I chose the Crossvalidation-error as my ultimate criteria. Significant level for variable to stay is 0.05.
5.Result: thankful for the sas easy usage, I got the following graph directly from the the result and modeling manager. This time I got 22 word frequency variables left as predictor, below is the result:
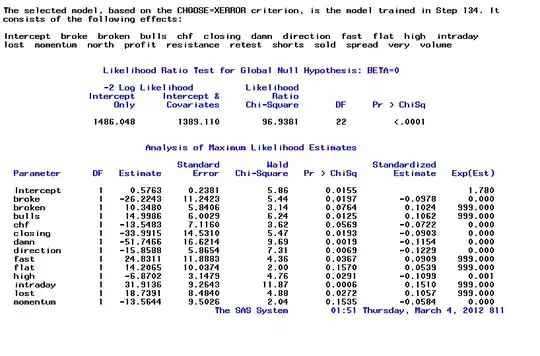
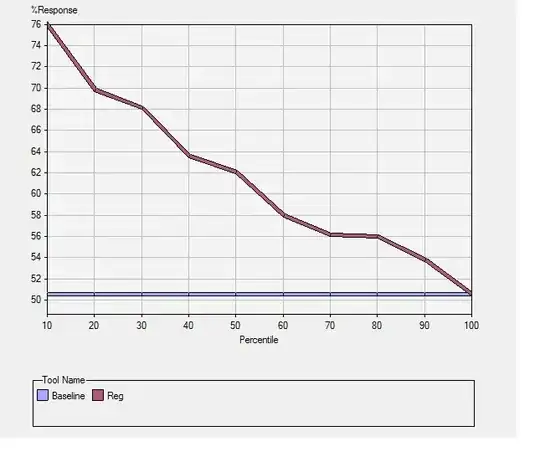
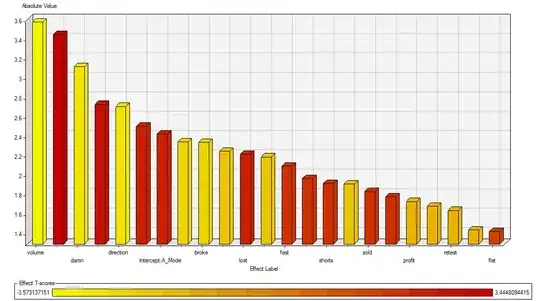
my naive interpretation about the three picture above. The goodness of fit is looking good. We got almost 76% accuracy of predicting on whether tomorrow is up or not and much better than the 50% baseline as random trader. The cumulative response chart also looks smooth. And we got 22 variable and it looks less scaring but still kind of heavy degree of freedom?
@PeterFlom, should I use proc glmmix here as you recommended over the shortage of backward selection on variables?
I pick up the top 10% day with highest score(predicted probability) from model above and do LONG, and bottom 10% day with lowest score from model above and do SHORT. The percentage gain is 50% from these 200 trading days out of 1000 days as dataset. Is this a good validation for model?