Thank you for you guys effort on building such a nice community and I learned lot by reading and asking.
Background about my logistic regression:
Target Variable: Binary target about volatility of market. "1" for trading days with top 15% percentile volatility day which indicates the extreme day on market. "0" for rest of normal and kind of calm day for market.
Predictor Variable: frequency of 160 trading related key words from famous trading online forum. For example, the word “trader” in 2008-01-01 we found it occurred for 50 times and we found in 2008-01-01 we have totally 500 posts on that forum. Therefore, we kind of normalize the appearance of "trader" by dividing 50 of "trader" by 500 of "number of posts". We got 0.1 here for 2008-01-01. We have 160 words dictionary and the training data is from 2008-01-01 to 2011-12-31. Each row has 160 column with number indicating the frequency of specific words. That is all. Nothing variable of price, volatility here. Kind of pure sentiment data based on frequency counting.
The Goal of Modelling: I think it is quite obvious that we would want to see whether we could have the sentiment words to be good predictor on whether tomorrow would be a EXTRAME VOLATILE DAY?
Software I use: SAS Enterprese Miner 3 in SAS 9.1.3. Here is definition and details of modeling:
A. I select logistic regression
B. No data partition because I only have 1000days as my training data so I select to use complete data which means no sampling process and only training data.
C. I select the backward as we want to see what are those significant predictor out of 160, here is some shortage if using forward.
D. There is no validation data set so I chose the Crossvalidation-error as my ultimate criteria. Significant level for variable to stay is 0.05.Result: thankful for the sas easy usage, I got the following graph directly from the the result and modeling manager:
First one is the result: as it shows how many variable left:
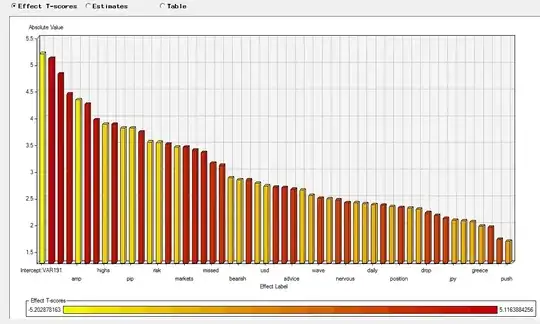
wow, so many variables... scaring.
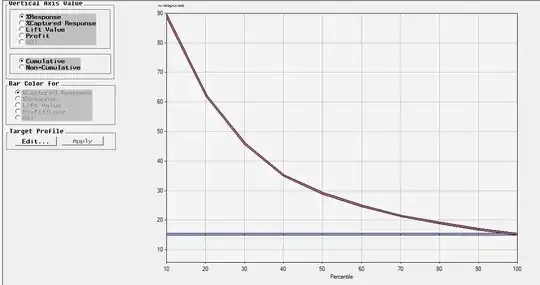
Second one about the response chart which indicates how much we improve the prediction compared to pure random pick or guessing about tomorrow, here, in my case, is about 15% chance you guess it right about whether tomorrow is a volatile day. Response chart looks nice and smooth, right?
WORRIING:
TOO MANY VARIABLE LEFT HERE. KIND OF SCARING. HOW DO I IMPROVE MODELLING AND INTERPRET THE RESULT?