Currently I'm working on my master thesis about the application of data mining in football, I'm trying to predict matches based on some stats of the two involved Teams (using RapidMiner).
My use case is the German Bundesliga and I will predict the last season (15/16) based on the three seasons before (12/13 to 14/15); the object to predict is the match result (home win, draw, away win).
Stats I am using are for example the market values of the teams (transfermarkt.de), the position in the table right before the match, the position at the end of the last season and some data to picture the 'form' of the teams, something like percentage of wins / goals shot / goals conceded / goal difference etc. in the last X matches. All in all I have like 20 attributes.
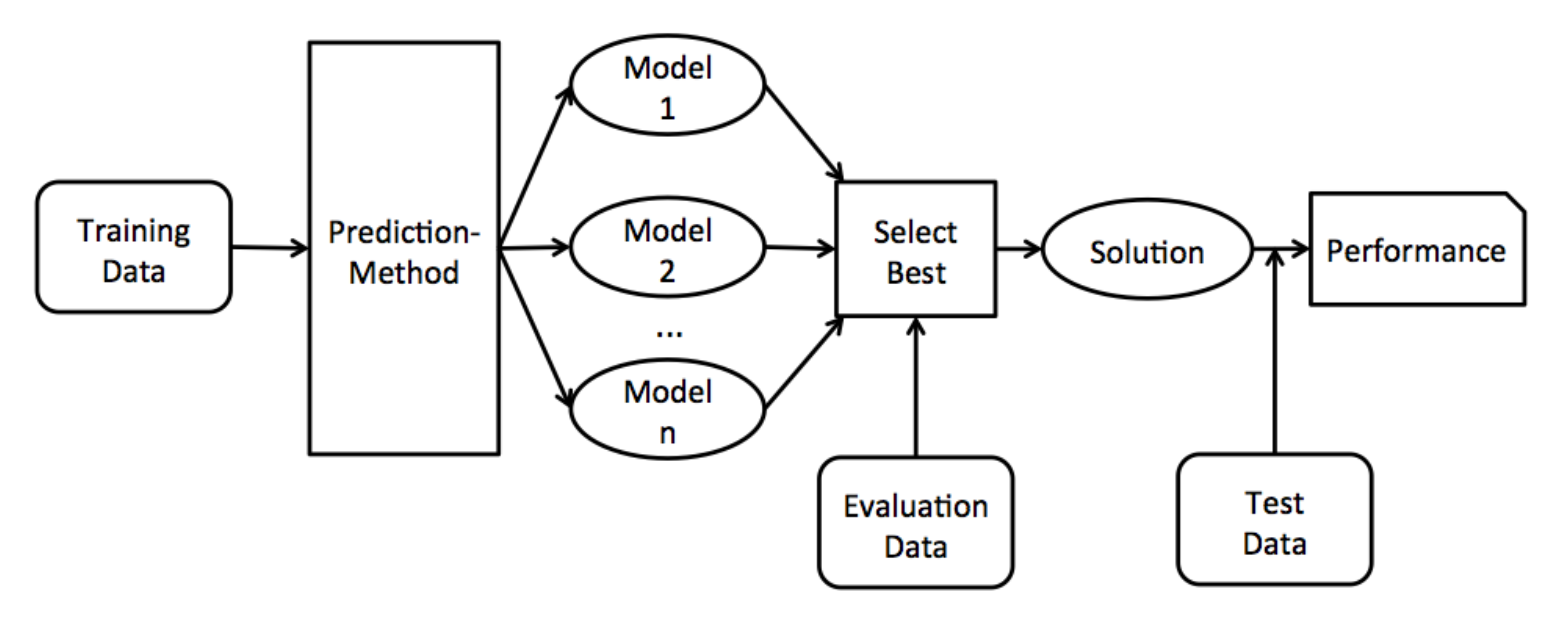
I already applied some algorithms on the data set, f.e. decision trees, neural nets, bayes rules and so on. But I don't know how to optimize my results. First approach would be like creating a very good model for the seasons 2012-2014 and apply it to 2015. But in this case, the model has a performance of something like 65% to 70% for the training data (with overfitting), but for the test data it's only like 47% to 49%.
Second approach was to change the optimization process to get a optimal model for 2015 (of course here the performance is way better), but this is not very realistic, because in reality you don't know the results of the season to predict, therefore this is not a valid way.
The only reasonable way is to create a model with the test data of 2012-2014 and then apply the model to 2015, where the model is neither optimized for 2012-2014, nor for 2015. It should somehow be a model with an average performance.
I thought about splitting up the test data, f.e. create a model with 2012+2013 and apply it to 2014 (or using Cross Validation); here i am able to do the optimization for 2014, since we know the results. Here i am getting a performance of something like 48% up to 53%, but this depends on my optimization parameters and the selection of my attributes. F.e. sometimes the algorithm finds a model, that has a performance of like 60% for the training data and 48% for the test data; sometimes the result is a model with 55% for the training data and 52% for the test data.
Any ideas on this topic?

{kind=link}