I am trying to solve for the parameters in the maximum entropy problem in R using the nonlinear system:
$\ \int_l^u e^{a+bx+cx^2}dx=1$
$\ \int_l^u x e^{a+bx+cx^2}dx=\mu$
$\ \int_l^u x^2 e^{a+bx+cx^2}dx=\mu^2+\sigma^2$
where $l$ and $u$ represent the lower and upper bound on the support of the distribution, and $a,b,c$ are the parameters of interest.
I wrote an implementation based on minimising the sum of the squared differences, and then optimising using BBoptim, but this method is very hit-or-miss, and depends heavily upon me inputting reasonable starting parameters, and quite tight lower and upper bounds on the range over which to search. I have included the code below:
MaxEnt <- function(y) {
G <- function(x) exp(y[1]+y[2]*x+y[3]*x^2) ;
H <- function(x) x*exp(y[1]+y[2]*x+y[3]*x^2) ;
I <- function(x) x^2*exp(y[1]+y[2]*x+y[3]*x^2) ;
(integrate(G, lower=l, upper=u)$value - 1)^2+(integrate(H, lower=l, upper=u)$value - mu)^2+(integrate(I, lower=l, upper=u)$value - mu^2-sd^2)^2}
BBoptim(c(-log(sqrt(2*pi)),0,0), MaxEnt, method=1)
Does anyone know of any better ways of doing what I am trying to achieve using R? Many thanks in advance.
============ EDIT JAN 17th ============
I have tried solving this problem using whuber's approach and so far this is what I get:
Let $\ y= \frac{x-l}{u-l}$. Then $\ dx = (u-l)dy$. Then since $\ x= (u-l)y+l$,
$\ a+bx+cx^2 = q+ry+cy^2$
where $\ q=a+bl+cl^2,r=(u-l)(b+2cl),s=c(u-l)^2$. The three original equations then become:
$\ \int_0^1 e^{q+ry+sy^2}dy=\frac{1}{u-l}$
$\ \int_0^1 ((u-l)y+l) e^{q+ry+sy^2}dy=\frac{\mu}{u-l}$
$\ \int_0^1 ((u-l)y+l)^2 e^{q+ry+sy^2}dy=\frac{\mu^2+\sigma^2}{u-l}$
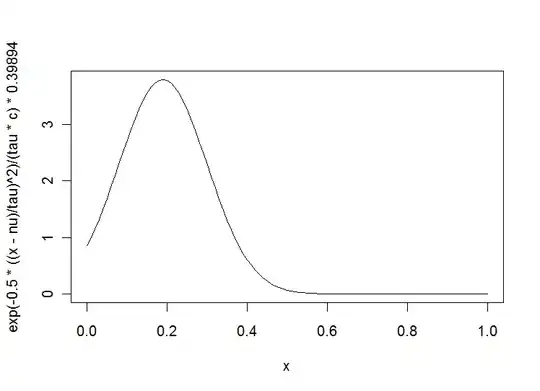
whuber then suggests rewriting $\ e^{q+ry+sy^2}$. Letting $\ \nu = \frac{-r}{2s}$ and $\ \tau = \sqrt{\frac{-1}{2s}}$ we can see that $\ e^{q+ry+sy^2} = e^{q-\frac{r^2}{2s}}e^{-0.5\left(\frac{y-\nu}{\tau}\right)^2}$.
The problem I now have is that using whubers approach we must have that $\ \tau^2 >0 $ (?). This means I need $\ s<0$. By definition, $\ s <0$ only if $\ c <0$ also. However, I have an example where the density that has maximum entropy has $c>0$. I am probably going wrong somewhere, and would be grateful if somebody could point out where. Thanks!