In this post @Wolfgang shares a few lines of code to test in a simulation the ability of a particular test statistic to perform as expected, measured by the percentage of type I errors. He shows by simulation how the $chi \,square$ test works in the case presented in that original post, despite the small number of "successes" in comparison with the large number of observations.
On a post I wrote to sort of piece together what I've been collecting from many other posts on comparison of proportions, I was trying to come up with a similar type of simulation using the $z$-test. I understand that the $\chi^2$ is mathematically equivalent in this situation, but it was one of these exercises in convincing oneself, and understand the $z \,test$ equations. Further, I wasn't sure the tests were going to be identical in every respect.
So to the question... I road-tested the equation of the $z$ test function, and it did not produce the expected results. The same happened with a similar ad hoc formula in R-Bloggers, which I will use in the rest of the question.
My bet is that my code is flawed (in which case, I'd like to fix it on my prior post), but the values it generates seem plausible; the only odd result being the proportion of type I errors. So I wonder if I could get some help, especially if the results are accurate, and the statistical interpretation is incorrect.
This is the actual problem (more details here if needed):
DATA:
Medication
Symptoms Drug A Drug B Totals
Heartburn 64 92 156
Normal 114 98 212
Totals 178 190 368
TEST STATISTIC FUNCTION IN R (from R-Bloggers):
For reference: $ Z = \frac{\frac{x_1}{n_1}-\frac{x_2}{n_2}}{\sqrt{p\,(1-p)(1/n_1+1/n_2)}}$ with $ p = \frac{x_1\,+\,x_2}{n_1\,+\,n_2}$
z.prop = function(x1,x2,n1,n2){
numerator = (x1/n1) - (x2/n2)
p.common = (x1+x2) / (n1+n2)
denominator = sqrt(p.common * (1-p.common) * (1/n1 + 1/n2))
z.prop.ris = numerator / denominator
return(z.prop.ris)
}
POPULATION SET UP WITH ONE SINGLE (AVERAGE) TRUE PROPORTION:
set.seed(5)
# Number of samples taken to obtain different proportions IF
# we set it up so that the proportions are actually equal:
samples <- 100000
# Number of cases for Drug A and Drug B:
n1 <- 178
n2 <- 190
# Proportion of patients with heartburn:
p1 <- 64/n1
p2 <- 92/n2
# We will make up a population where the proportion of heartburn suffers
# is in between p1 and p2:
(c(p <- mean(c(p1, p2)), p1, p2))
[1] 0.4218805 0.3595506 0.4842105
# And we'll take samples of the size of the groups assigned to Drug A
# and Drug B respectively:
x1 <- rbinom(samples, n1, p)
x2 <- rbinom(samples, n2, p)
# Double - checking that the proportion is kept although the number of
# successes is different:
(c(mean(x1),mean(x2)))
[1] 75.08542 80.15841
(c(prop1 <- mean(x1)/n1, prop2 <- mean(x2)/n2, p))
[1] 0.4218282 0.4218864 0.4218805
SIMULATION:
# Now we run the z-test in what we just did, but we repeat it 100000 times
# and put the results in vector pval:
pval <- 0
for (i in 1:100000) {
pval[i] <- pnorm(-abs(z.prop(mean(x1[i]), mean(x2[i]), n1, n2)))
}
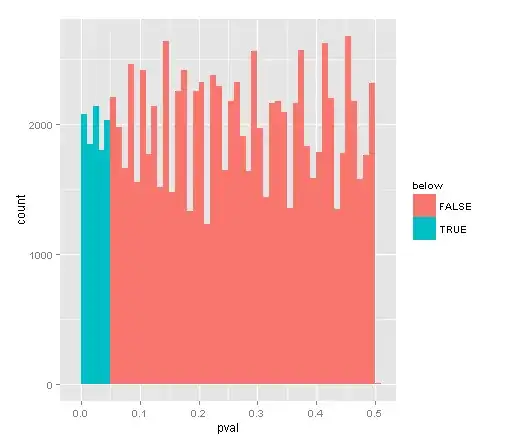
# What is the fraction of pval's below 0.05 (it should be 0.05 since we
# should only reject 0.05 times the true NULL):
mean(pval <= .05)
[1] 0.09887
To my surprise, the result is 0.09887, and changing the set.seed ends up with larger proportions of falsely rejected null hypothesis.