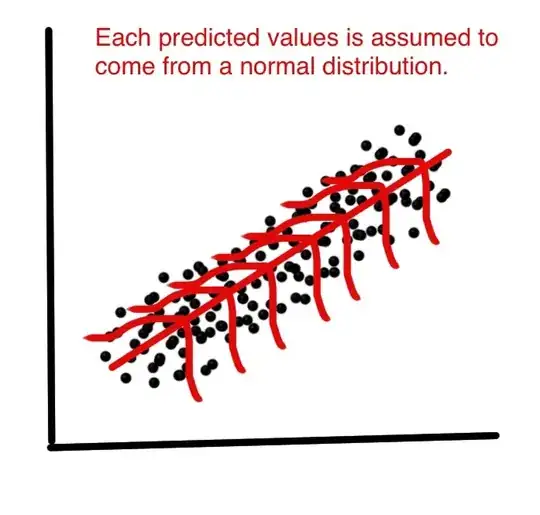
Linear regression by itself does not need the normal (gaussian) assumption, the estimators can be calculated (by linear least squares) without any need of such assumption, and makes perfect sense without it.
But then, as statisticians we want to understand some of the properties of this method, answers to questions such as: are the least squares estimators optimal in some sense? or can we do better with some alternative estimators? Then, under the normal distribution of error terms, we can show that this estimators are, indeed, optimal, for instance they are "unbiased of minimum variance", or maximum likelihood. No such thing can be proved without the normal assumption.
Also, if we want to construct (and analyze properties of) confidence intervals or hypothesis tests, then we use the normal assumption. But, we could instead construct confidence intervals by some other means, such as bootstrapping. Then, we do not use the normal assumption, but, alas, without that, it could be we should use some other estimators than the least squares ones, maybe some robust estimators?
In practice, of course, the normal distribution is at most a convenient fiction. So, the really important question is, how close to normality do we need to be to claim to use the results referred to above? That is a much trickier question! Optimality results are not robust, so even a very small deviation from normality might destroy optimality. That is an argument in favour of robust methods. For another tack at that question, see my answer to Why should we use t errors instead of normal errors?
Another relevant question is Why is the normality of residuals "barely important at all" for the purpose of estimating the regression line?
EDIT
This answer led to a large discussion-in-comments, which again led to my new question: Linear regression: any non-normal distribution giving identity of OLS and MLE? which now finally got (three) answers, giving examples where non-normal distributions lead to least squares estimators.