I have a data set that contains outliers (big orders) i need to forecast this series taking the outliers into consideration. I already know what the top 11 big orders are so i dont need to detect them first. I have tried a few ways to deal with this 1) forecast the data 10 times each time replacing the biggest outlier with the next biggest until the last set is run with them all replaced and then compare results 2) forecast the data another 10 times removing the outliers in each until they are all removed in the last set. Both of these work but they dont consistently give accurate forecasts. I was wondering if anyone knew another way to approach this?
One way i was thinking was running a weighted ARIMA and work it so that less/minimal weight is put on those specific data points. Is this possible?
I just want to point out that removing the known outliers does not delete that point completely, only minimizes it as there are other deals that happened in that quarter
One of my data sets is the following:
data <- matrix(c("08Q1", "08Q2", "08Q3", "08Q4", "09Q1", "09Q2", "09Q3", "09Q4", "10Q1", "10Q2", "10Q3", "10Q4", "11Q1", "11Q2", "11Q3", "11Q4", "12Q1", "12Q2", "12Q3", "12Q4", "13Q1", "13Q2", "13Q3", "13Q4", "14Q1", "14Q2", "14Q3", "14Q4",155782698, 159463653.4, 172741125.6, 204547180, 126049319.8, 138648461.5, 135678842.1, 242568446.1, 177019289.3, 200397120.6, 182516217.1, 306143365.6, 222890269.2, 239062450.2, 229124263.2, 370575382.9, 257757410.5, 256125841.6, 231879306.6, 419580274, 268211059, 276378232.1, 261739468.7, 429127062.8, 254776725.6, 329429882.8, 264012891.6, 496745973.9),ncol=2,byrow=FALSE)
the known outliers in this series are:
outliers <- matrix(c("14Q4","14Q2","12Q1","13Q1","14Q2","11Q1","11Q4","14Q2","13Q4","14Q4","13Q1",20193525.68,18319234.7,12896323.62,12718744.01,12353002.09,11936190.13,11356476.28,11351192.31,10101527.85,9723641.25,9643214.018),ncol=2,byrow=FALSE)
please do not say about seasonality as this is only one type of data set, i have many ones without seaonality and i need the code to work for both types.
Edit by javlacalle: This is a plot of the observed data and the time points defined in the first column of outliers.
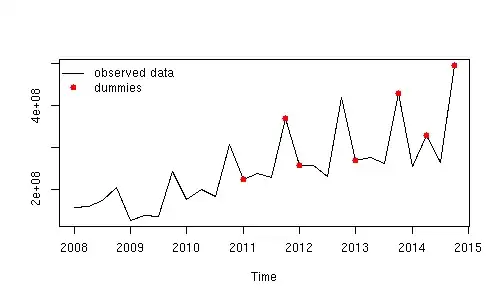
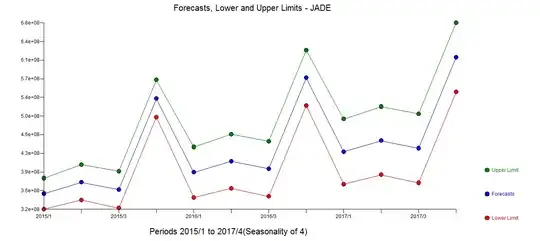
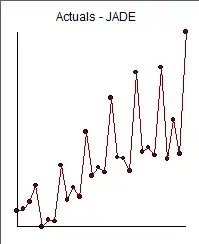 suggest the following model including two outlier adjustments
suggest the following model including two outlier adjustments  The two outliers (low values) can be seen here in the actual/cleansed plot
The two outliers (low values) can be seen here in the actual/cleansed plot 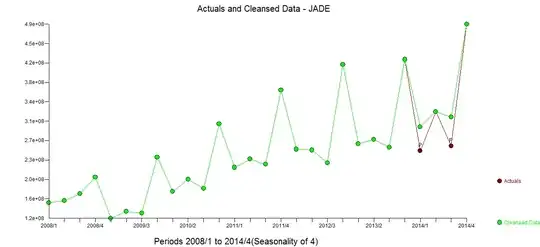 . The model generated the following residuals
. The model generated the following residuals 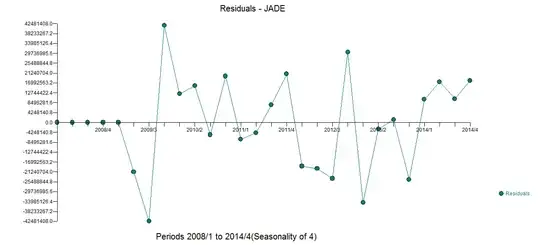 which are free of any apparent auto-correlative structure
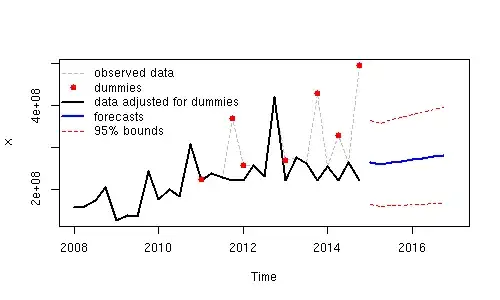
which are free of any apparent auto-correlative structure 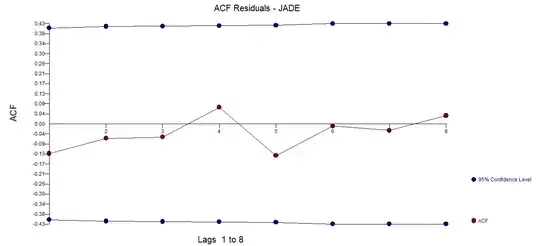 . The forecasts reflect the adjustment for the two anomalies
. The forecasts reflect the adjustment for the two anomalies