My question is why Multiple Linear Regression (MLR), based on least squares, cannot be built when the number of variables $(p)$ are larger than the number of samples $(n)$?
Can one explain why is it like this?
My question is why Multiple Linear Regression (MLR), based on least squares, cannot be built when the number of variables $(p)$ are larger than the number of samples $(n)$?
Can one explain why is it like this?
I will provide a visual in a very simple case because it is the easiest case to visualize. Imagine you are trying to fit the following linear model: $Y\sim \alpha + X\beta + \epsilon$. In this situation you have two parameters, $\alpha$ and $\beta$, and imagine you only have a sample size of $n=1$.
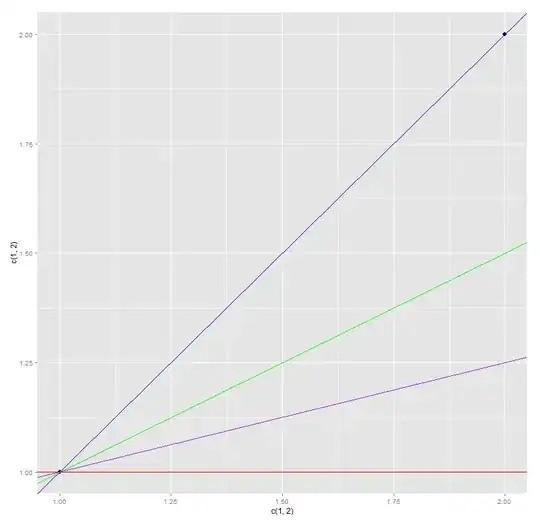
Your single piece of data is represented by the black dot below. Notice all the lines we can fit through this point! Each of these lines are the line of best fit as they all minimize your SSE to 0.
There are in fact infinite lines through this point. You can see this because the data point above is $(1,1)$ and there are infinite solutions to $1=\alpha + \beta$. Now, try to generalize this to thinking of fitting a plane in three dimensional space when you only have two pieces of data $(n=2)$. You will find a similar issue there.
What happens when we try to fit the same model, $Y\sim \alpha + X\beta + \epsilon$, when we have two points of data represented by the two black dots below? In other words, what happens when $n \geq p$?
The blue line above uniquely beats every other line we can draw on this graph in terms of SSE. In other words, there is no other line that would provide as good a fit as the blue line.
If you are not satisfied with a visual explanation, let's think about this in matrix notation. Recall, in multiple linear regression $\hat{\beta}_{p\times1} = [(X^TX)^{-1}X^T]_{p\times n}Y_{n\times1}$. We can equivalently write this as $[(X^TX)^{-1}X^T]_{n\times p}^{-1}\hat{\beta}_{p\times1} = Y_{n\times1}$ by taking the left inverse on each side. If you are familiar with linear algebra, you'll see that $\hat{\beta}$ is the solution to a system of $n$ equations with $p$ unknowns. There is no unique solution to this system when the number of unknowns, $p$, is larger than $n$!
I believe what Nick was saying in his comment is: your MLR with N variables is trying to fix N values (coefficients) in N-dimensional space, but you are trying to do it with M (M < N) pieces of data. How will you do this?
Since you only have M data points, the other M-N dimensions of your answer are free-floating, as happens when trying to define a line through a single point (2D problem with only one sample) or a plane through two points (3D problem with only 2 samples).
In the case of a line through a point: you have a single sample and you're trying to determine the slope and intercept of a line through it. You can arbitrarily pick a slope and that determines your intercept, or you can arbitrarily pick an intercept and it determines your slope, but you are not doing this from the sample. You have an infinite number of choices, all arbitrary.
If you have two points, the line through them is determined unambiguously. If you have many points and are doing OLS, the line goes through the "center" of the cloud of points in some sense, but it is still unambiguous by the rules of OLS.
Analyst's answer is in fact correct. If p>n you end up with an underdetermined system and can use pseudo-inverse to solve it.
When you have more parameters than equations as in this case, using pseudo-inverse finds the minimum euclidian norm solution.
This is the best assumption you can do since this solution has the lowest variance. That is also what you achieve with ridge regression but in a different way. We want this since, given a model $Y=Xb$, if there is noise in measurement $X$ i.e $X_n=X+n$, then estimate $Y=X_n b$ will have an error of $nb$ that its value depends on norm of $b$.
I ignored the constant parameter because one can set it equal to the average of samples and use the above model to estimate the rest.
If P, number of variables, is larger than N number of observations then you have underdetermined system of equations.
There exist pseudo-inverse which can solve this:
http://people.csail.mit.edu/bkph/articles/Pseudo_Inverse.pdf