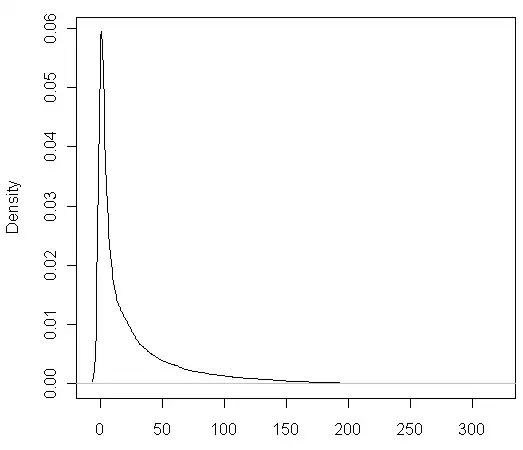
It's not usually possible to identify a distribution from looking at a histogram like this.
As a start, plot the density on a log scale:
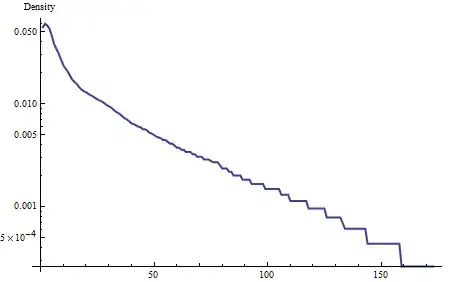
The tail of this density (from around 40 onward) is close to linear, showing it is close to exponential. That's part of the characterization. To go further, compare the density to this characterization by forming the residuals (on a log scale, effectively taking the ratio of the density to an exponential curve):
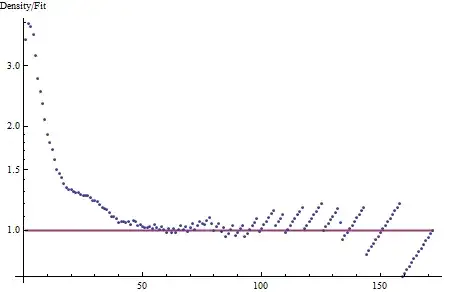
Clearly this density is not exponential: for small values it is almost four times greater than the exponential fit to the tail would indicate. We must go further with the characterization.
We seek to characterize the residuals as simply as possible: this means in terms of longish straight segments or parabolic sections. (On this log scale, a straight segment is an exponential trend, whereas a parabolic section looks like a piece of a Normal distribution.) Evidently there are two parabolic-like sections: a sharp peaked one centered near 1 and a shallow, broad one centered near 25-30. The first would correspond to a healthy part of a truncated Normal distribution with small standard deviation (around 5-6) whereas the second would correspond to most of a Normal distribution with a larger standard deviation (around 10 perhaps). This indicates the density is not going to be adequately described by a simple mathematical formula, such as a Gamma or Weibull, but perhaps it can be decomposed into a mixture of two or three components. Look for each of those components to have some meaning: could these data indeed involve some combination of phenomena tending to occur near 1, near 25, and out beyond 40?