Now, I understand that this depends on distributions and normality in predictors
log transforming does make data more uniform
As a general claim, this is false --- but even if it were the case, why would uniformity be important?
Consider, for example,
i) a binary predictor taking only the values 1 and 2. Taking logs would leave it as a binary predictor taking only the values 0 and log 2. It doesn't really affect anything except the intercept and scaling of terms involving this predictor. Even the p-value of the predictor would be unchanged, as would the fitted values.
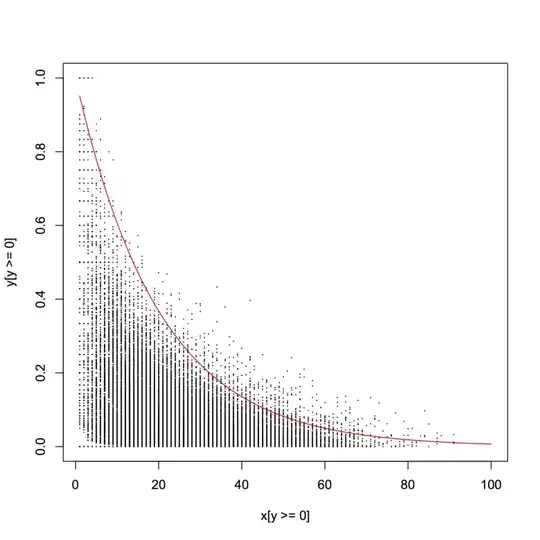
ii) consider a left-skew predictor. Now take logs. It typically becomes more left skew.
iii) uniform data becomes left skew
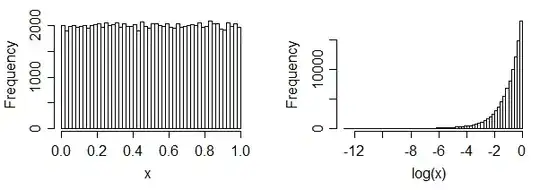
(it's often not always so extreme a change, though)
less affected by outliers
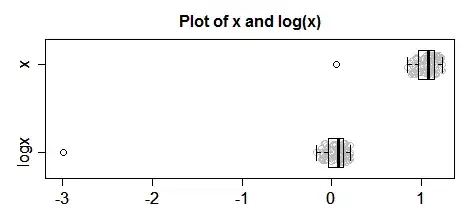
As a general claim, this is false. Consider low outliers in a predictor.
I thought about log transforming all my continuous variables which are not of main interest
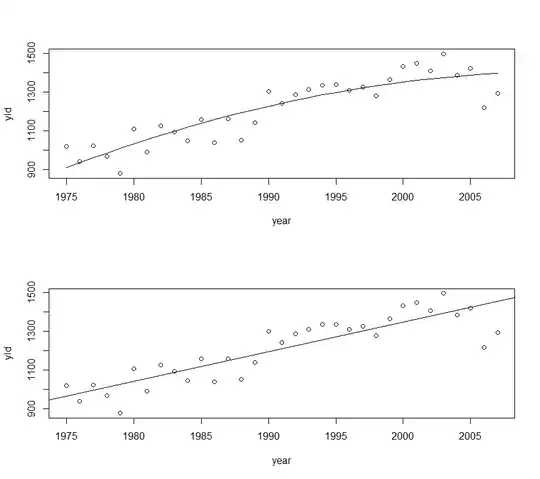
To what end? If originally the relationships were linear, they would not longer be.
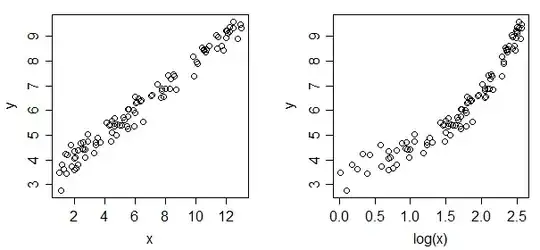
And if they were already curved, doing this automatically might make them worse (more curved), not better.
--
Taking logs of a predictor (whether of primary interest or not) might sometimes be suitable, but it's not always so.