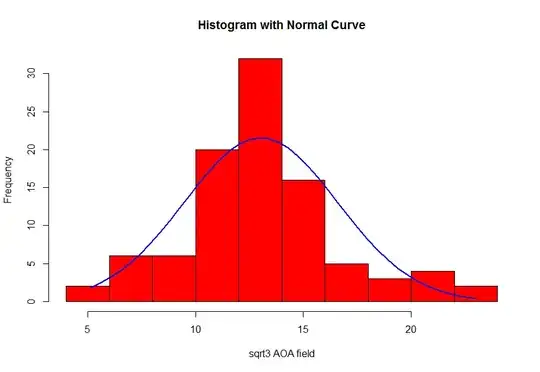
This is the graph of my variable after the $\sqrt[3]{x}$-transformation. After the transformation, I ran a Shapiro test and obtained a $p$-value of $0.004262$. Is it possible my transformed variable is normally distributed? The size of my dataset is 240 samples.
The summary is:
Sample Time Treatment
Min. : 1.0 Min. : 0.0 Control:24
1st Qu.:112.8 1st Qu.: 7.0 TBCZ_x1:24
Median :180.5 Median : 24.5 TBCZ_x2:24
Mean :193.2 Mean : 38.5 TBCZ_x5:24
3rd Qu.:312.2 3rd Qu.: 70.0
Max. :360.0 Max. :105.0
sqrt_AOA_field sqrt4_AOA_field sqrt3_AOA_field
Min. : 11.63 Min. : 3.410 Min. : 5.133
1st Qu.: 37.90 1st Qu.: 6.156 1st Qu.:11.282
Median : 45.42 Median : 6.739 Median :12.730
Mean : 48.30 Mean : 6.809 Mean :13.026
3rd Qu.: 54.95 3rd Qu.: 7.413 3rd Qu.:14.453
Max. :110.45 Max. :10.510 Max. :23.021
If you need other information write me here. Thanks so much Jo