There is a univariate mean: sum the points and divide by the count.
There is a multivariate mean analog - the centroid, a point in a multidimensional space. (1).
For the median one sorts the list and picks the middle element. If the middle element doesn't exist, the nearest values to it are averaged. (2) It is an ordered statistic.
If I were to make a cloud of points in 2d space, then median might depend on what I defined as an axis. If my cloud was more like a needle, then median might vary greatly with very slight changes in semi-minor axis, because it could flip from one tip to another of the cloud.
Is there a generalized geometric analog of the mean - something that uses an analog of an ordered statistic in a non-univariate space? If I had well behaved cloud, even if it was more needle-like, I would expect such a median to have a reasonable correlation with and proximity to a centroid.
It was suggested that this (link) contains the answer. When I try to find the point that gives the least typical distance, the results are consistent with a geometric mean.
#CODE
n <- 1000
xmin <- 0
xmax <- 10
ymin <- 0
ymax <- 10
#make some points
x <- runif(n,min=xmin,max=xmax)
y <- runif(n,min=ymin,max=ymax)
#plot
plot(x,y,type="p")
#find "geometric median"
mu <- 0
for (i in 1:n){
xp <- x[i]
yp <- y[i]
d <- sqrt( (x-xp)^2 + (y-yp)^2 )
mu[i] <- mean(d)
}
idx <- which(mu==min(mu),arr.ind=true)
points(x[idx],y[idx],col="Red",pch=16)
points(mean(x),mean(y),col="Blue",pch=17)
I get plots that look like the following. The red point is the "idx" of the least typical distance to all other points. The blue triangle is the centroid. The red circle is the "geometric median".
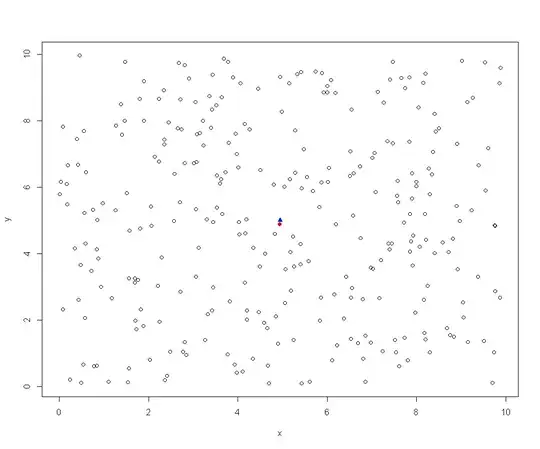
To me the image seems to confirm that the approach to the median is consistent with the mean. I have not accounted for an odd number of points, but I think that using uniform random and an $$ L_2 $$ norm is unlikely to give me two candidate medians with the same distance to all other points.
So I tried to determine the error in the estimate of the median from the true center as a function of sample size. I wanted to make sure that I have acceptable sample sizes for my intended end-use of this approach. I repeated the test ~3000 times per sample size setting and chose the median distance as representative. In general the results for repeated tests to find the median on ~3000 runs had variation only in the 3d decimal place.
Here is the table of values of distance from the true center as a function of sample size.
samples err
10 2.008
15 1.676
20 1.456
25 1.317
30 1.198
35 1.124
50 0.930
90 0.698
100 0.659
300 0.386
I used Eureqa to try and determine the analytic form that is best described by the fit. It looks like the following is the appropriate model. AIC gives it as a decent candidate.
$$ Err(n) = \frac {6.5}{\sqrt{n}}$$
The domain is between 0 and 10 in x and y. The value $ n $ is the number of samples. Err is the distance between the median median and the true center.
Questions:
- Can you confirm/reject that the general approach is correct based on the consistency between the median and the mean as a result from the code?
- Is the general form as spoken ground-up from the numbers as opposed to top-down by theory consistent with the textbook results from what the theory says it should be? What is the appropriate expression there and how should it be derived?
- The denominator is expected, but where does the 6.5 in the numerator come from? If my domain were a cube or a hypercube what should I expect of the numerator?
References and suggestions are always welcome.