Transforming X doesn't impact the shape of the conditional distribution, nor heteroskedasticity, so transforming X really only serves to deal with nonlinear relationships. (If you're fitting additive models it might serve to help with eliminating interaction, but even that's often best left to transforming Y)
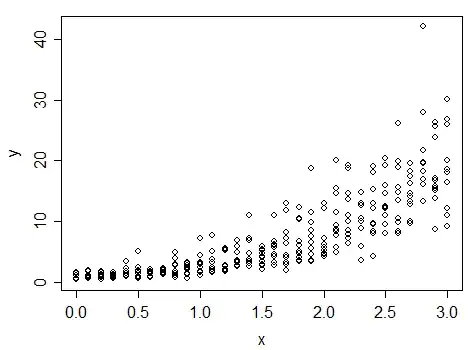
An example where transforming only X makes sense:
If that's - lack of fit in conditional mean - is your main issue, then transforming X may make sense, but if you're transforming because of the shape of the conditional Y or because of heteroskedasticity, if you're solving that by transformation (not necessarily the best choice, but we're taking transformation as a given for this question), then you must transform Y in some way to change it.
Consider, for example, a model where conditional variance is proportional to mean:
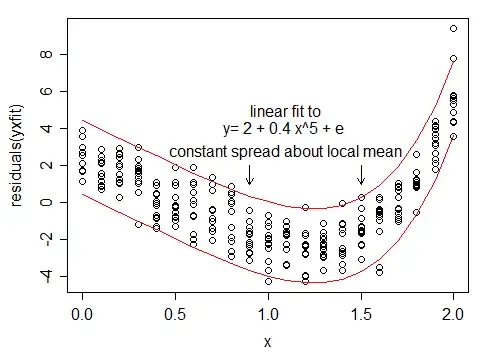
An example where transforming only X can't solve the problems:
Moving values on the x-axis won't change the fact that the spread is greater for values on the right than values on the left. If you want to fix this changing variance by transformation, you have to squish down high Y-values and stretch out low Y-values.
Now, if you're considering transforming Y, that will change the shape of the relationship between response and predictors ... so you'll often expect to transform X as well if you want a linear model (if it was linear before transforming, it won't be afterward). Sometimes (as in the second plot above), a Y=transformation will make the relationship more linear at the same time - but it's not always the case.
If you're transforming both X and Y, you want to do Y first, because of that change in the shape of the relationship between Y and X - usually you need to see what relationships are like after you transform. Subsequent transformation of X will then aim to obtain linearity of relationship.
So in general, if you're transforming at all, you often need to transform Y, and if you're doing that, you nearly always want to do it first.