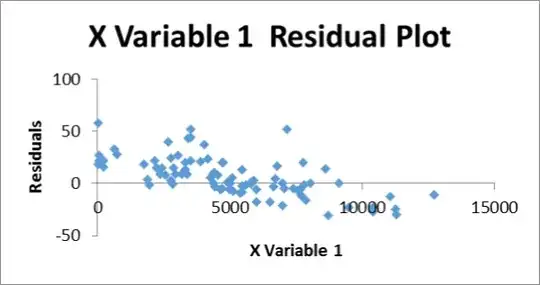
Yes, the residual plots for variables 1 & 2 are problematic. I don't necessarily see any heterogeneity of variance (heteroscedasticity), or even non-linearity, but they certainly show non-independence. You can very clearly guess if a residual will be above or below 0 based on whether its neighbors are.
I do want to clear up a small misunderstanding. You state that you think there may be too many residuals below 0. It isn't that 50% of the residuals must be <0, and 50% above, rather the assumption is that the mean of the residuals is 0. If you have some skew in the distribution of the residuals, the mean won't equal the median, and you can validly have different numbers greater or less than 0.
I am perplexed, though. The OLS algorithm should ensure that what you see in your top two plots does not happen in regression. What code / program did you use to fit the data and generate these residuals? Did you force the intercept to be 0? That is the only thing I can think of that would produce the plots you show.



1.) I am trying to predict productivity of finishing a task in the warehouse using quantity of work (# of pcs to do) and ratio of pcs/SKU. pcs and pcs/SKU both contains same information, # of pcs. Is this a violation of independent variables?
2.) do both y and x variables need to be normally distributed? I believe p-value assume normality? – palm May 23 '14 at 04:45