Say I have a large sample of values in $[0,1]$. I would like to estimate the underlying $\text{Beta}(\alpha, \beta)$ distribution. The majority of the samples come from this assumed $\text{Beta}(\alpha, \beta)$ distribution, while the rest are outliers that I would like to ignore in the estimation of $\alpha$ and $\beta$.
What is a good way to proceed about this?
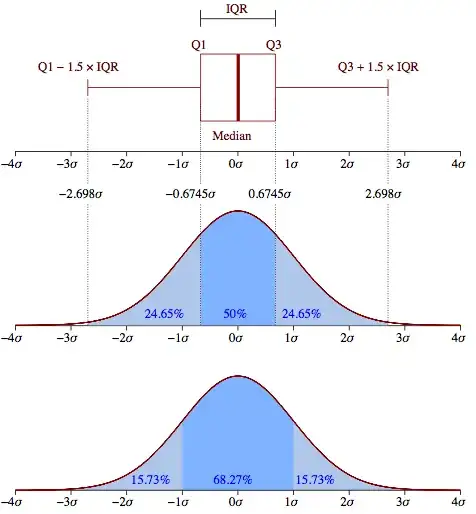
Would the standard: $\text{Inliers} = \left\{x \in [Q1 - 1.5\, \text{IQR}, Q3 + 1.5 \,\text{IQR}] \right\}$ formula used in boxplots be a bad approximation?
What would a more principled way of solving this? Are there any particular priors on $\alpha$ and $\beta$ that would work well in this type of problem?