There are two elements to @Peter's example, which it might be useful to disentangle:
(1) Model mis-specification. The models
$$y_i = \beta_0 + \beta_1 x_i + \varepsilon_i \qquad\text{(1)}$$
&
$$w_i=\gamma_0 + \gamma_1 z_i + \zeta_i \qquad\text{(2)}$$
, where $w_i=\sqrt{\frac{y_i}{x_i}}$ & $z_i=\sqrt{x_i}$, can't both be true. If you re-express each in terms of the other's response they become non-linear in the parameters, with heteroskedastic errors.
$$w_i = \sqrt{\frac{\beta_0}{z_i^2} + \beta_1 + \frac{\varepsilon_i}{z_i^2}} \qquad\text{(1)}$$
$$y_i = (\gamma_0 \sqrt x_i + \gamma_1 \sqrt x_i + \zeta_i \sqrt x_i)^2 \qquad\text{(2)}$$
If $Y$ is assumed to be a Gaussian random variable independent of $X$, then that's a special case of Model 1 in which $\beta_1=0$, & you shouldn't be using Model 2. But equally if $W$ is assumed to be a Gaussian random variable independent of $Z$, you shouldn't be using Model 1. Any preference for one model rather than the other has to come from substantive theory or their fit to data.
(2) Transformation of the response. If you knew $Y$ & $X$ to be independent Gaussian random variables, why should the relation between $W$ & $Z$ still surprise you, or would you call it spurious? The conditional expectation of $W$ can be approximated with the delta method:
$$ \operatorname{E} \sqrt\frac{Y}{x} = \frac{\operatorname{E}\sqrt{Y}}{z} \\
\approx \frac{\sqrt{\beta_0} + \frac{\operatorname{Var}{Y}}{8\beta_0^{3/2}}}{z}$$
It is indeed a function of $z$.
Following through the example ...
set.seed(123)
x <- rnorm(100, 20, 2)
y <- rnorm(100, 20, 2)
w <- (y/x)^.5
z <- x^.5
wrong.model <- lm(w~z)
right.model <- lm(y~x)
x.vals <- as.data.frame(seq(15,25,by=.1))
names(x.vals) <- "x"
z.vals <- as.data.frame(x.vals^.5)
names(z.vals) <- "z"
plot(x,y)
lines(x.vals$x, predict(right.model, newdata=x.vals), lty=3)
lines(x.vals$x, (predict(wrong.model, newdata=z.vals)*z.vals)^2, lty=2)
abline(h=20)
legend("topright",legend=c("data","y on x fits","w on z fits", "truth"), lty=c(NA,3,2,1), pch=c(1,NA,NA,NA))
plot(z,w)
lines(z.vals$z,sqrt(predict(right.model, newdata=x.vals))/as.matrix(z.vals), lty=3)
lines(z.vals$z,predict(wrong.model, newdata=z.vals), lty=2)
lines(z.vals$z,(sqrt(20) + 2/(8*20^(3/2)))/z.vals$z)
legend("topright",legend=c("data","y on x fits","w on z fits","truth"),lty=c(NA,3,2,1), pch=c(1,NA,NA,NA))
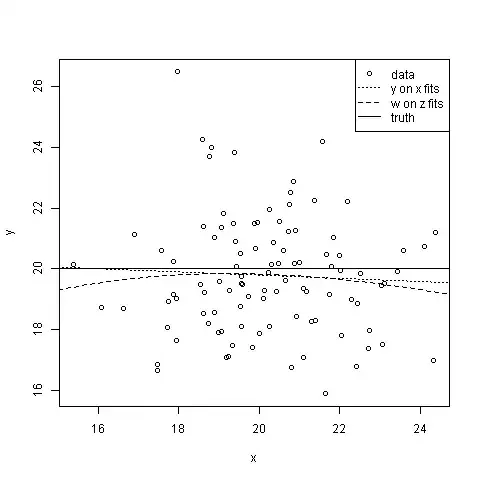
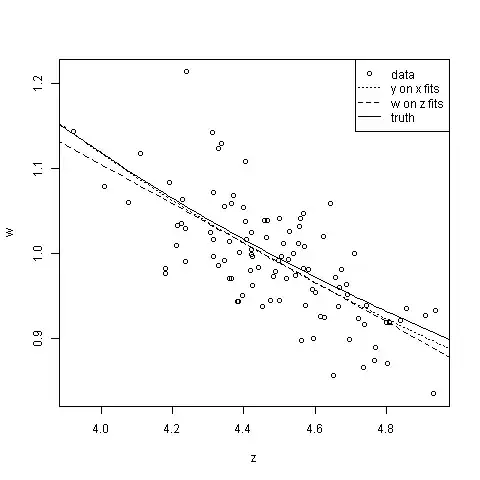
Neither Model 1 nor Model 2 is much use for predicting $y$ from $x$, but both are all right for predicting $w$ from $z$: mis-specification hasn't done much harm here (which isn't to say it never will—when it does, it ought to be apparent from the model diagnostics). Model-2-ers will run into trouble sooner as they extrapolate further away from the data—par for the course, if your model's wrong. Some will gain pleasure from contemplation of the little stars they get to put next to their p-values, while some Model-1-ers will bitterly grudge them this—the sum total of human happiness stays about the same. And of course, Model-2-ers, looking at the plot of $w$ against $z$, might be tempted to think that intervening to increase $z$ will reduce $w$—we can only hope & pray they don't succumb to a temptation we've all been incessantly warned against; that of confusing correlation with causation.
Aldrich (2005), "Correlations Genuine and Spurious in Pearson and Yule", Statistical Science, 10, 4 provides an interesting historical perspective on these issues.