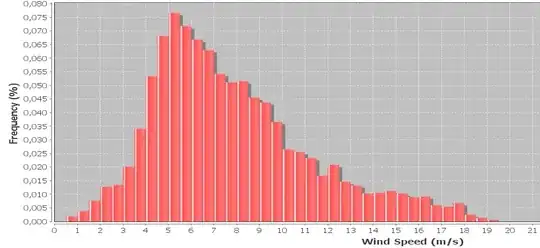
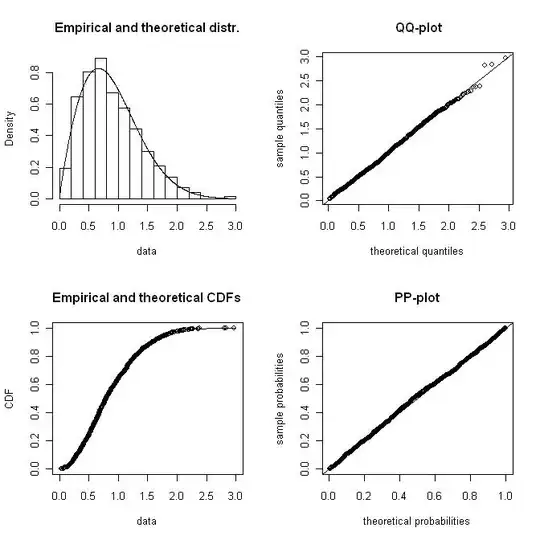
Maximum Likelihood Estimation of Weibull parameters may be a good idea in your case. A form of Weibull distribution looks like this:
$$(\gamma / \theta) (x)^{\gamma-1}\exp(-x^{\gamma}/\theta)$$
Where $\theta, \gamma > 0$ are parameters. Given observations $X_1, \ldots, X_n$, the log-likelihood function is
$$L(\theta, \gamma)=\displaystyle \sum_{i=1}^{n}\log f(X_i| \theta, \gamma)$$
One "programming based" solution would be optimize this function using constrained optimization. Solving for optimum solution:
$$\frac {\partial \log L} {\partial \gamma} = \frac{n}{\gamma} + \sum_1^n \log x_i - \frac{1}{\theta}\sum_1^nx_i^{\gamma}\log x_i = 0 $$
$$\frac {\partial \log L} {\partial \theta} = -\frac{n}{\theta} + \frac{1}{\theta^2}\sum_1^nx_i^{\gamma}=0$$
On eliminating $\theta$ we get:
$$\Bigg[ \frac {\sum_1^n x_i^{\gamma} \log x_i}{\sum_1^n x_i^{\gamma}} - \frac {1}{\gamma}\Bigg]=\frac{1}{n}\sum_1^n \log x_i$$
Now this can be solved for ML estimate $\hat \gamma$. This can be accomplished with the aid of standard iterative procedures which solve are used to find the solution of equation such as -- Newton-Raphson or other numerical procedures.
Now $\theta$ can be found in terms of $\hat \gamma$ as:
$$\hat \theta = \frac {\sum_1^n x_i^{\hat \gamma}}{n}$$