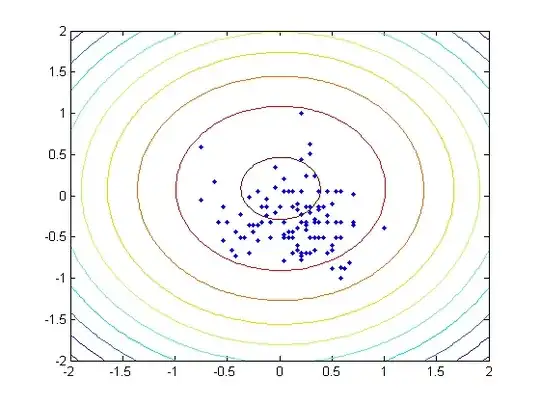
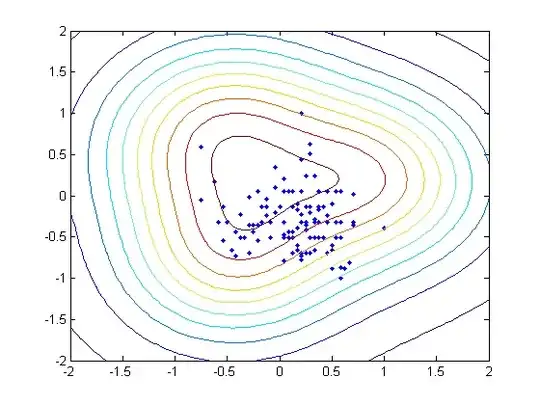
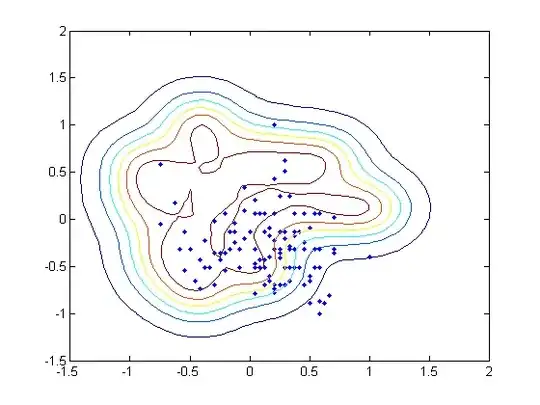
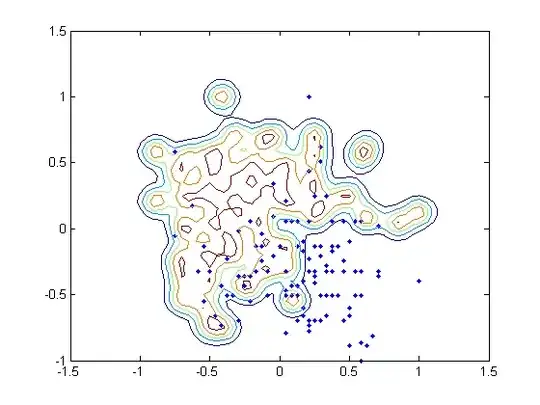
I am using the heart_scale data from LibSVM. The original data includes 13 features, but I only used 2 of them in order to plot the distributions in a figure. Instead of training the binary classifier, I treated the problem as a one-class SVM by only selecting the data labelled +1.
The $\nu$ is fixed to $0.01$ in my case, and I tried 6 different $\gamma$ values for my RBF kernel: $10^{-3}$, $10^{-2}$, $10^{-1}$, $10^{0}$, $10^{1}$, and $10^{2}$. Theoretically small $\gamma$ may lead to high bias and low variance, while large $\gamma$ may get the reverse, and tend to overfitting. However, my result indicates the statement above is only partially true.
As $\gamma$ increases, the number of support vectors are 3, 3, 3, 7, 35, and 89.
On the other hand, however, the training accuracy (the corrected classified data among 120) is 117, 118, 119, 117, 96, and 69. The training error increases dramatically.
I also tried to deal with the binary classifier, and the relation between $C$, $\gamma$ and the variance/bias performance is consistent with the 'theory' trend.
I was trying to understand why this 'contradiction' occurs with one class SVM.
I attached the contour of the 6 different hyperplanes below as well.