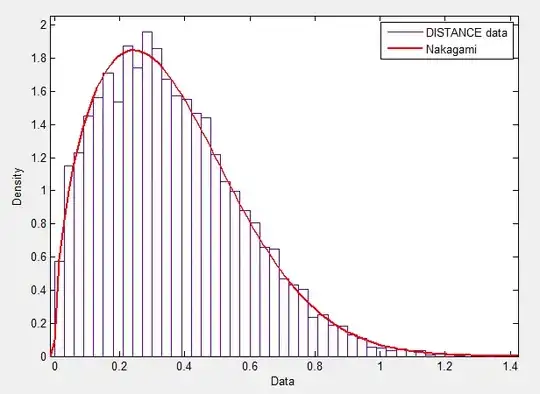
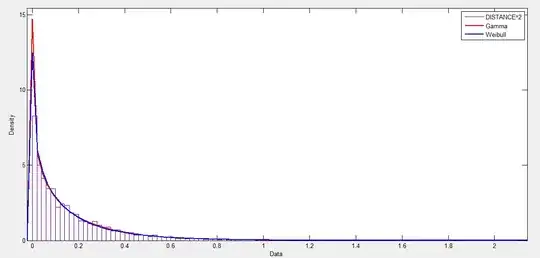
With respect to post (1) and post (2), I generated a large number of uniformly distributed points inside the ball of radius $R$ using $\frac{R_s U^{1/3}}{\sqrt{X_1^2 + X_2^2 + X_3^2}} (X_1, X_2, X_3)$, where $U$ is uniformly distributed between 0 and 1, and $X_1, X_2, X_3$ are independent normal random variables with mean 0 and variance 1.
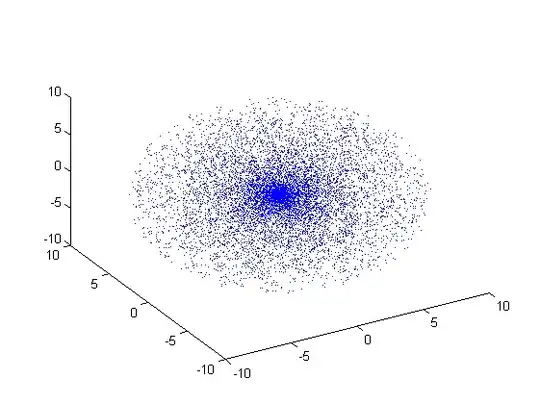
The following figure shows a uniform spherical distribution obtained by this method using 10000 independent draws in a sphere of radius 10.
By computing the nearest neighbour distance $d_i$ of every point, I observed that the diagnostic plot of nearest neighbour distances does not follow a uniform distribution. Does this non-uniform distribution mean that one can cluster the points? Does it mean points dont have spatial randomness? If so, then how can I generate random points with uniform nearest neighbour distances.
Temporary images for @Anony-Mousse consideration: