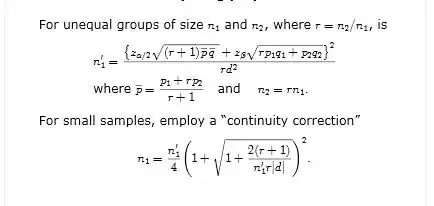Update: 2014-02-06: changed text to be more emphatic that fpc should not be used in a causal analysis
**Update: 2014-02-04: impact of the randomized experimental design
This question has raised some fundamental issues.
You stated in your update that a researcher can control the make-up of the experimental groups. Not so. Even if one randomized an entire population, there would be imbalance, perhaps trivial, in every variable. Even with some kind of balancing algorithm, which would destroy the randomization, one can never arrange for identity of the means of the outcome variable, yet unmeasured.
You also asked Tom Lumley:
Are you saying it is legitimate to estimate the confidence interval of say, the difference between the proportion of men and women answering 'Yes' but not a p-value to determine if it is zero (i.e. to reject the null)?
I think that's what Tom meant, and I agree with its application to descriptive statistics; I'm not sure that it applies It does not apply to causal analyses, including those generated by an experiment. Your particular example is a borderline case, as you intend the results to apply to a single population at a particular time. If someone asked you to project your findings to another setting or to another time period, the confidence interval calculation probably should not include the fpc.
Some additional insight can be gained by considering the experimental design as part of the sample design. If the initial random sample is of size $n$, randomization produces two random sub-samples of size $n_1 = n/2$ and $n_2 = n/2$. (For the theory that follows, $n_1$ and $n_2$ need not be equal.) Let $\overline{y}_1$ and $\overline{y}_2$ be the means of the sub-samples; proportions are special cases. In this scenario, which conforms to the absence of a treatment effect, it can be shown (Cochran, 1977, problem 2.16, p. 48) that:
\begin{equation}
Var(\overline{y}_1 -\overline{y}_2) = S^2\left(\frac{1}{n_1} +\frac{1}{n_2}\right)
\end{equation}
where $S^2$ is the population variance and variation is over repetitions of the sampling and randomization. Notice: no fpc.
Update: one of the few established uses of hypothesis tests + FPCs for finite populations: lot quality assurance sampling (LQAS)
I agree with Tom's answer. Hypothesis testing rarely has a place in finite population questions, but confidence intervals certainly do. One good use of hypothesis tests per se in finite populations is lot quality assurance sampling (LQAS), which tests whether the rate of some event (e.g. vaccination) in a geographic area is too high or too low. Note that, unlike the question at hand, there is no hypothesis of zero difference. The null hypothesis is that the rate is < K, and the alternative that is it is $\geq$K. See, at Google Scholar.
Robertson, Susan E, Martha Anker, Alain J Roisin, Nejma Macklai, Kristina Engstrom, and F Marc LaForce. 1997. The Lot quality technique: a global review of applications in the assessment of health services and disease surveillance. Relation 50, no. 3/4: 199-209.
Lemeshow, Stanley, and Scott Taber. 1991. Lot quality assurance sampling: single-and double-sampling plans. World Health Stat Q 44, no. 3: 115-132.
Original Answer
Using the fpc to reduce sample size makes no sense unless intend you use it in the the hypothesis-testing statistic. But that would be an error: the fpc should not be used when testing hypotheses [added about "no difference"].
The reasoning is interesting (Cochran, 1977, p.39): It is seldom of scientific interest to ask if a null hypothesis (e.g. that two proportions are equal) is exactly true in a finite population . Except by a very rare chance, the null hypothesis will never be true, as one would discover by enumerating the entire population. Therefore hypothesis tests on samples from finite populations are done from a "super-population" viewpoint. See also Deming (1966) pp 247-261 "Distinction between enumerative and analystic studies"; Korn and Graubard (1999), p. 227.
References
Cochran, W. G. (1977). Sampling techniques (3rd ed.). New York: Wiley.
Deming, W. E. (1966). Some theory of sampling. New York: Dover Publications.
Korn, E. L., & Graubard, B. I. (1999). Analysis of health surveys (Wiley series in probability and statistics). New York: Wiley.