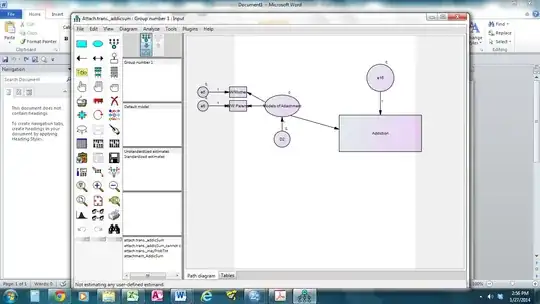
I am VERY new to SEM. I ran a model where I obtained 0 DF, so it could not compute the fit. So, I am left to cut out parameters. HOWEVER, I'm not sure where I can cut them in my particular case. I have attached here a screenshot of my model...you can see there are not too many parameters. I am trying to test to see if Emotional Models of Attachment (measured by early relationships) affect level addiction (measured in the survey).
I'm not sure how I can cut down parameters without losing the whole meaning. For example, I can cut out the latent variable, and just look at the data as a path analysis from the early relationship measures to Addiction... but that would eliminate the theory that Attachment Models are involved, right?
Also, in researching more about constraining, I read that I can set the regression (number by the arrow) at 1. But in my case, this would sort of ruin the whole point of running my model, correct? When is good practice to constrain from a latent variable?
Thank you!