I have two types of samples:
- some look like bimodal Gaussian mixture (Type A),
- and some look like a Gaussian (Type B).
How can I programmatically classify/label them?
Language can be R, Python, Matlab, or anything else appropriate.
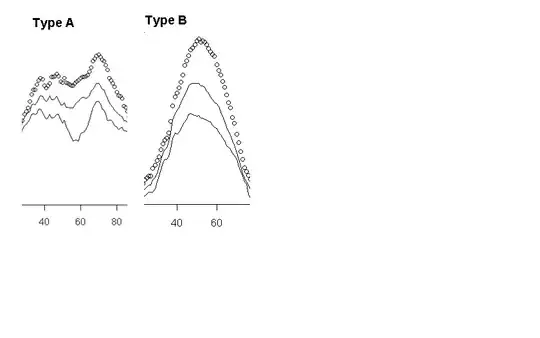
The data presented in the charts are Red values from jpeg images.
In R code:
# I read an image
I = readJPEG(file, native = FALSE)
# so I is now a matrix of 3 dimensions (rows, columns, 3 for Red/Green/Blue)
# I extract a vertical line from the image, and only the Red part
image_extract <- I[150:260, 194, 1]
# After reading several images, I plot the 3 images image_extract for each type (A,B)
plot(image_extract_1)
lines(image_extract_2)
lines(image_extract_3)
For Type A I plotted, 3 image extracts on the same chart. Same for Type B.
I hope it clarifies.