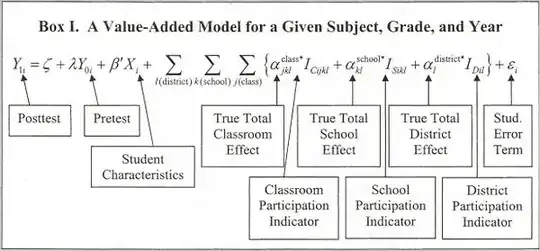
Here's one possibility.
Assessing teacher performance has traditionally been difficult. One part of this difficulty is that different students have different levels of interest in a given subject. If a given student gets an A, this doesn't necessarily mean that teaching was excellent -- rather, it may mean that a very gifted and interested student did his best to succeed even despite poor teaching quality. Conversely, a student getting a D doesn't necessarily mean that the teaching was poor -- rather, it may mean that a disinterested student coasted despite the teacher's best efforts to educate and inspire.
The difficulty is aggravated by the fact that student selection (and therefore the students' level of interest) is far from random. It is common for schools to emphasize one subject (or a group of subjects) over others. For example, a school may emphasize technical subjects over humanities. Students in such schools are probably so interested in technical areas that they will receive a passing grade even with the worst possible teacher. Thus the fraction of students passing math is not a good measure of teaching -- we expect good teachers to do much better than that with students who are so eager to learn. In contrast, those same students may not be interested at all in arts. It would be difficult to expect even from the best teacher to ensure all students get A's.
Another difficulty is that not all success in a given class is attributable to that class's teacher directly. Rather, the success may be due to the school (or entire district) creating motivation and framework for achievement.
To take into account all of these difficulties, researchers have created a model that evaluates teacher's 'added value'. In essence, the model takes into account the intrinsic characteristics of each student (overall level of interest and success in learning), as well as the school and district's contributions to student success, and predicts the student grades that would be expected with 'average' teaching in that environment. The model then compares the actual grades to the predicted ones and based on it decides whether teaching was adequate given all the other considerations, better than adequate, or worse. Although the model may seem complex to a non-mathematician, it is actually pretty simple and standard. Mathematicians have been using similar (and even more complex) models for decades.
To summarize, Ms. Isaacson's guess is correct. Even though 65 of her 66 students scored proficient on the state test, they would have scored just the same even if a dog were their teacher. An actual good teacher would enable these students to achieve not merely 'proficient', but actually 'good' scores on the same test.
At this point I could mention some of my concerns with the model. For example, the model developers claim it addresses some of the difficulties with evaluating teaching quality. Do I have enough reasons to believe them? Neighborhoods with lower-income population will have lower expected 'district' and 'school' scores. Say a neighborhood will have an expected score of 2.5. A teacher that will achieve an average of 3 will get a good evaluation. This may prompt teachers to aim for the score of 3, rather than for a score of, say, 4 or 5. In other words, teachers will aim for mediocrity rather than perfection. Do we want this to happen? Finally, even though the model is simple mathematically, it works in a way very different from how human intuition works. As a result, we have no obvious way to validate or dispute the model's decision. Ms. Isaacson's unfortunate example illustrates what this may lead to. Do we want to depend blindly on the computer in something so important?
Note that this is an explanation to a layperson. I sidestepped several potentially controversial issues here. For example, I didn't want to say that school districts with low income demographics are expected to perform poorer, because this wouldn't sound good to a layperson.
Also, I have assumed that the goal is actually to give a reasonably fair description of the model. But I'm pretty sure that this wasn't NYT's goal here. So at least part of the reason their explanation is poor is intentional FUD, in my opinion.