When running a model with a categorical predictor, the output contains n-1 p.values where n is the number of levels in the factor. One level is taken to be the reference group.
For example: I observed plants in different environments and want to know if the substrate1, substrate2 and substrate3 (categorical non-ordinal predictors) influence the height, number of leaves and weight (response variables) of the plants.
My question is: Which group should be the reference? Note: None of the group might be consider as a control group or as a normal group while the others are differ from what is normal. For example I will run the three models.
Heigth ~ substrate1 + ... weigth ~ substrate1 + ... Number_of_leaves ~ substrate1 + ...
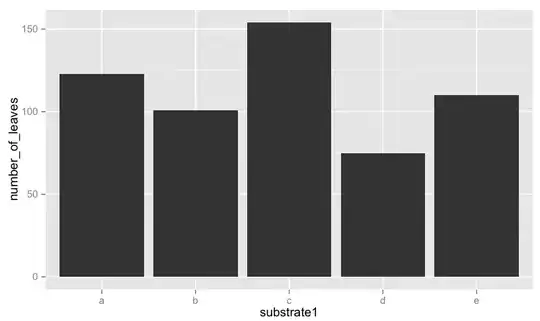
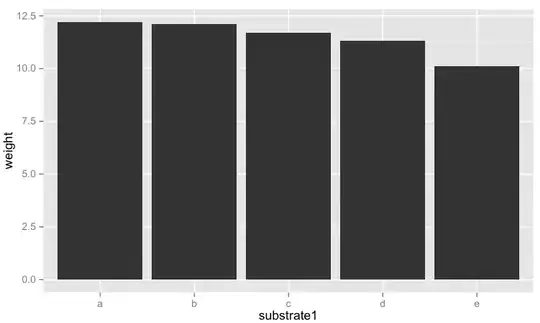
substrate1 is made of 5 groups: 'a','b','c','d','e'. It non-ordinal!
Which group of substrate1 would you suggest me to choose as the reference group for each model?
- One of the two extreme group (even if it is not the same group in each model)
- The group which is the closest to the overall mean (even if it is not the same group in each model)
- The group which contain the greatest number of observations
- Any group but it is better to always chose the same group
Here are some graphs to make more sense of my question. Should I always choose group 'c' or should I chose 'c' for the first model, 'd' for the second model and 'e' for the last model. Or other...