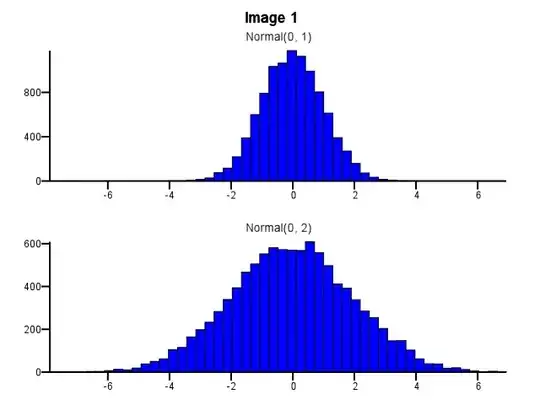
Let's say I have two distributions I want to compare in detail, i.e. in a way that makes shape, scale and shift easily visible. One good way to do this is to plot a histogram for each distribution, put them on the same X scale, and stack one underneath the other.
When doing this, how should binning be done? Should both histograms use the same bin boundaries even if one distribution is much more dispersed than the other, as in Image 1 below? Should binning be done independently for each histogram before zooming, as in Image 2 below? Is there even a good rule of thumb on this?