I haven't found a satisfactory answer for this problem by reading previous related posts. There are a total of $10,000,000$ observations with the following observed and expected frequencies:
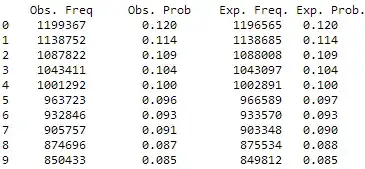
A goodness-of-fit $\chi^2$-test comparing the observed data to the expected probabilities yields a value of $25.97749$ with $p$-value $.002$. This result seems--at least to the non-expert--quite shocking given how similar the observed distribution is to the expected distribution.
If I draw less observations (in fact, Obs. Freq come from simulations), say $1000$, then the $\chi^2$-test gives a $p$-value close to 1.
1) Is there a formal way to know when are we using too much observations?
2) Is there a goodness-of-fit test that can handle $10,000,000$ observations?
Any help is appreciated.
EDIT: Just some background of the data and the purpose of the test. The simulations come from multiplying normal and exponential distributions; the observed frequencies reported are those of the 2nd significant digits of these simulations. The expected frequencies come from what Benford's law for the 2nd significant digit predicts.
So the table show that the simulated variables follow closely what is predicted by Benford's law. The reason why the table is not enough is that we would like to automatize the analysis for several datasets and detect whenever a deviation occurs.