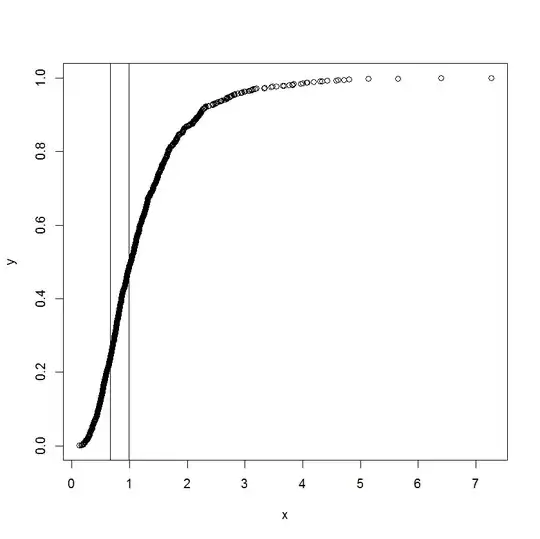
I have been given this task and was stumped. A colleague asked me to estimate the $x_{upper}$ and $x_{lower}$ of the following chart:
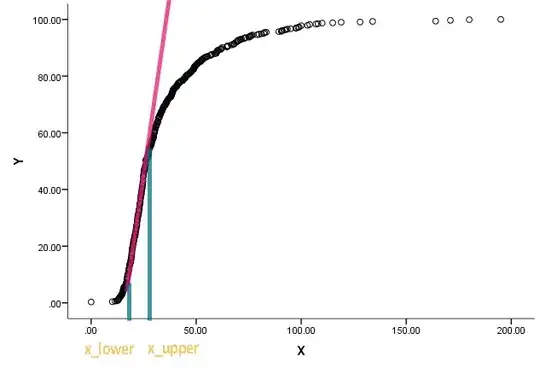
The curve is actually a cumulative distribution, and x is some kind of measurements. He is interested to know what are the corresponding values on x when the cumulative function started to become straight and deviate from being straight.
I understand that we can use differentiation to find the slope at a point, but I am not too sure how to determine when can we call the line straight. Any nudge towards some already existing approach/literature will be greatly appreciated.
I know R as well if you happen to know any relevant packages or examples on this kind of investigations.
Thanks a lot.
UPDATE
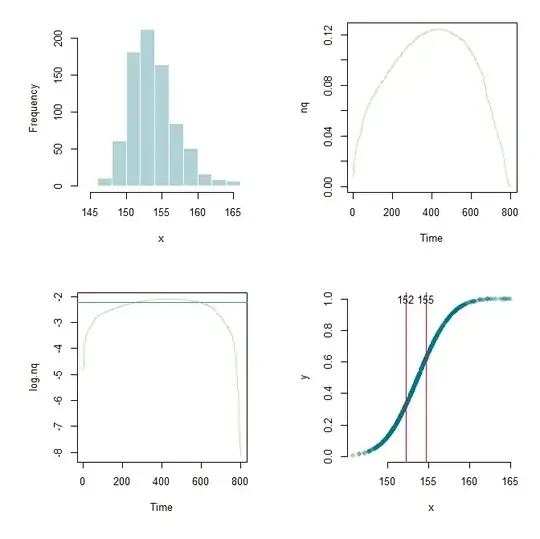
Thanks to Flounderer I was able to expand the work further, set up a framework, and tinker the parameters here and there. For learning purpose here are my current code and a graphic output.
library(ESPRESSO)
x <- skew.rnorm(800, 150, 5, 3)
x <- sort(x)
meanX <- mean(x)
sdX <- sd(x)
stdX <- (x-meanX)/sdX
y <- pnorm(stdX)
par(mfrow=c(2,2), mai=c(1,1,0.3,0.3))
hist(x, col="#03718750", border="white", main="")
nq <- diff(y)/diff(x)
plot.ts(nq, col="#6dc03480")
log.nq <- log(nq)
low <- lowess(log.nq)
cutoff <- .7
q <- quantile(low$y, cutoff)
plot.ts(log.nq, col="#6dc03480")
abline(h=q, col="#348d9e")
x.lower <- x[min(which(low$y > q))]
x.upper <- x[max(which(low$y > q))]
plot(x,y,pch=16,col="#03718750", axes=F)
axis(side=1)
axis(side=2)
abline(v=c(x.lower, x.upper),col="red")
text(x.lower, 1.0, round(x.lower,0))
text(x.upper, 1.0, round(x.upper,0))