Is it possible to apply the usual MLE procedure to the triangle distribution? - I am trying but I seem to be blocked at one step or another in the math by the way the distribution is defined. I am trying to use the fact that I know the number of samples above and below c (without knowing c): these 2 numbers are cn and (1-c)n, if n is the total number of samples. However, that does not seem to help in the derivation. The moment of moments gives an estimator for c without much problem. What is the exact nature of the obstruction to MLE here (if indeed there is one)?
More details:
Let's consider $c$ in $[0,1]$ and the distribution defined on $[0,1]$ by:
$f(x;c) = \frac{2x}{c}$ if x < c
$f(x;c) = \frac{2(1-x)}{(1-c)}$ if c <= x
Let's take an $n$ i.i.d samples $\{x_{i}\}$ from this distribution form the log-likelihood of c given this sample:
$\hat{l}(c | \{x_{i}\}) = \sum_{i=1}^{n}ln(f(x_{i}|c))$
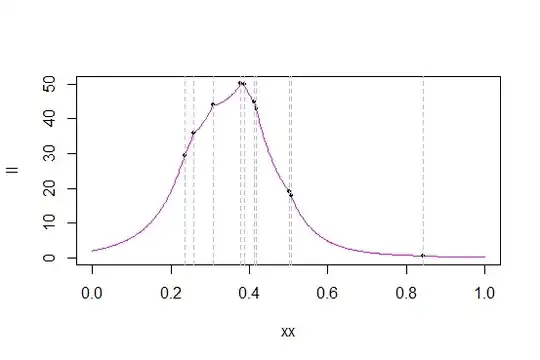
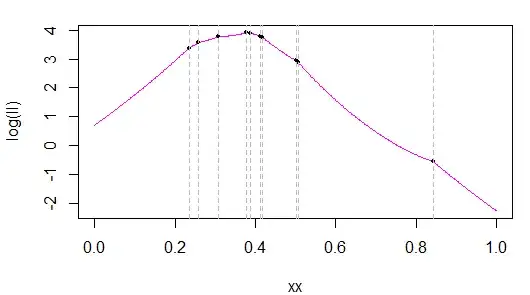
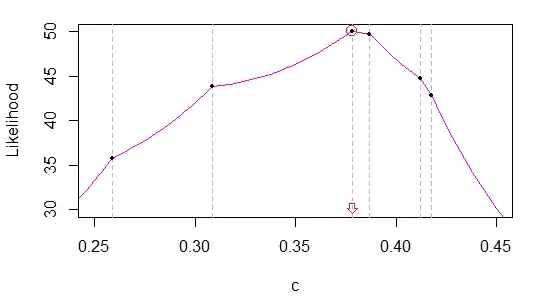
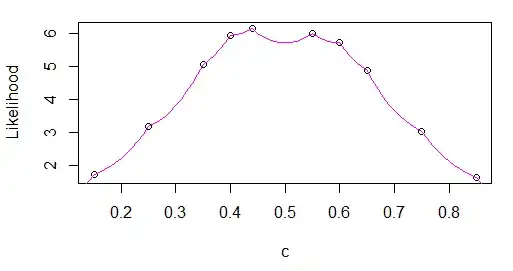
I am then trying to use the fact that given the form of $f$, we know that $cn$ samples will fall below the (unknown) $c$, and $(1-c)n$ will fall above $c$. IMHO, this allows to decompose the summation in the expression of the log-likelihood thus:
$\hat{l}(c | \{x_{i}\}) = \sum_{i=1}^{cn}ln\frac{2 x_{i}}{c} + \sum_{i=1}^{(1-c)n}ln\frac{2(1-x_{i})}{1-c}$
Here, I am unsure how to proceed. MLE will involve taking a derivative w.r.t. $c$ of the log-likelihood, but I have $c$ as the upper bound of the summation, which seems to block that. I could try with another form of the log-likelihood, using indicator functions:
$\hat{l}(c | \{x_{i}\}) = \sum_{i=1}^{n}\{x_{i}<c\}ln\frac{2 x_{i}}{c} + \sum_{i=1}^{n}\{c<=x_{i}\}ln\frac{2(1-x_{i})}{1-c}$
But deriving the indicators doesn't seem easy either, although Dirac deltas could allow to continue (while still having indicators, since we need to derive products).
So, here I am blocked in MLE. Any idea?