I have a problem which I am trying to fit into a classical regression/learning framework.
I have a dataset $D$ where each instance $d_i$ is a set of $(x,y)$ pairs, where $x$ is a non-negative number representing a position and $y$ is a non-negative value. For example, one $d_i$ could look like this:
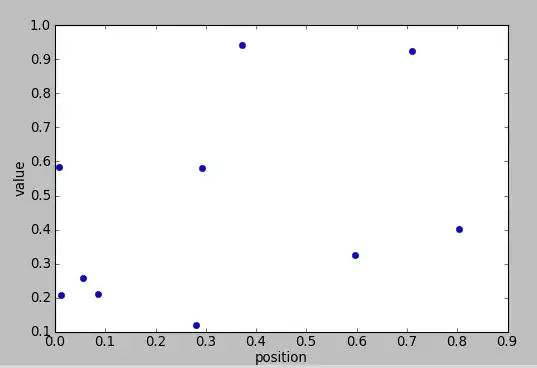
Given a vector of non-negative numbers $p$, I want to find a function $f$ which maps each $d_i$ to $p_i$ as well as possible, e.g. using least-squares minimizes $(f(d_i)-p_i)^2$. For example, such a function could be taking the the average of the $x$ values weighted by $y$, i.e. $f(d_i)=\frac{1}{\sum{y_j}}\sum{y_j*x_j}$. In general, the function will have some parameters, which I want to fit. For example, in the above example I could decide to use only the $k$ highest $y_j$ values, and I want to find the best $k$.
There are two straightforward ways to put this into a classical regression framework:
- Define $d_i$ as a vector of $y$ values, where the coordinate in the vector encodes the position $x$. This will be a problem since the $d_i$ vectors will be very sparse and at a given position most $d_i$ vectors will tend to have missing values.
- Define $d_i$ as a vector of $(x_i,y_i)$ pairs (e.g. one could "flatten" this to make it a 1d vector). The problem is then that I am artificially introducing coordinates, and so a general regression function might use the coordinates. This is a bad thing since the pairs are unordered so I expect $f(d_i)$ to be the same regardless of the order of the $(x,y)$ pairs.
I think this problem may be equivalent to this question: Learning from unordered tuples?, but I am not quite sure it is exactly the same - am I overlooking some natural ordered representation?