For each user, you have two time series, lat(t) and long(t). I think that's the simplest representation -- I wouldn't try to complicate things by converting to some definition of turns, which would not only be more difficult, but also would require being very careful about the initial starting point and treating it differently in any analysis. (It's probably noisier as well.)
Keeping the data as lat & long time series also keeps it simple for the most likely use -- where you will look at a various time windows at different times - there's no need to constantly recalculate a starting point at the beginning of a new time window being analyzed.
If every users' time series lat & long were all sampled at the exact same times, as noted in another reply you can just concatenate the two time series vectors into one long vector. A similar example that had 5 time series looked like this:
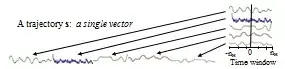 . Then you have one long vector for each user that you can analyze just like any other vector for pattern recognition, distance measures, clustering, etc.
. Then you have one long vector for each user that you can analyze just like any other vector for pattern recognition, distance measures, clustering, etc.
For distance measures between users, you're typically going to use a weighted form depending on the application. For instance, when focusing on convergence towards a common destination, you'd increase the weights the most towards the end of the time window (whether looking at euclidean calculations, max distance, etc.).
But, the original question seems to say that there may be differing numbers of points between A and B for different users. And in any case, even for the same sampling interval, it's likely that that the times aren't exactly the same (maybe differing by some constant because sampling started at different times). Furthermore, it's quite possible that there will be some missing data. In any of these cases, conceptually, you'd need to think of each time series in continuous form, perhaps fitting a curve to it, and resampling every user at the exact same times. (That's analogous to the resampling that occurs in photo analysis when you shrink a picture). Then your time series vectors for lat & long are the same length and correspond exactly to the same times, so that the concatenated vectors for each user over some time period can be compared to each other correctly.